
Cost-Efficient Memory Expansion Strategies for LLM Apps
Optimizing memory for LLM applications involves layered strategies: KV cache optimizations like PagedAttention can improve throughput by 2-4x, prompt compression reduces tokens by up to 20x while maintaining accuracy, and episodic memory architectures can cut token usage by over 90%. Combined with semantic caching achieving 70% hit rates and proper vector database selection, teams can reduce infrastructure costs by 60-80% while improving response quality.
At a Glance
• KV Cache Optimization: PagedAttention and adaptive eviction methods like SAGE-KV deliver 2-4x throughput improvements with up to 70% memory reduction
• Prompt Compression: LLMLingua-2 achieves 3-6x faster compression than existing methods while maintaining 98.5% performance at 20x compression ratios
• Memory Architecture Trade-offs: Sub-O(n) memory methods suffer in multi-turn scenarios, while sparse encoding with O(n) memory performs robustly for production workloads
• Cost Comparison: Vector database selection can mean the difference between $64/month and $660/month for 10M vectors, with semantic caching reducing LLM API costs by up to 70%
• Hardware Acceleration: Processing-in-Memory systems like PIMphony achieve performance boosts up to 11.3x for extreme context lengths exceeding 128K tokens
Memory expansion for LLM applications has become a critical concern as long-context inference drives up GPU VRAM usage and API bills. Teams building production AI agents face a stark reality: naive approaches to handling extended contexts can spike KV-cache memory by 6-10x and push latency past acceptable thresholds. This guide ranks optimization options from KV-cache tweaks to episodic memory layers, helping CTOs and engineers select strategies that balance performance with budget constraints.
Why Does Memory Expansion Matter for Production LLMs?
Long-context LLMs have enabled numerous downstream applications but also introduced significant efficiency challenges. For teams shipping AI agents, understanding why memory expansion matters is the first step toward building sustainable infrastructure.
Large Language Models encounter severe memory inefficiencies during long-context inference due to conventional handling of key-value (KV) caches. The KV cache grows linearly with sequence length, layers, and embedding dimensions, following the formula Memory=O(n⋅L⋅d). For a 70B parameter model processing 128K tokens, this can consume tens of gigabytes of GPU memory for a single request.
The financial impact compounds quickly. Key-Value caches are the silent performance backbone of modern LLM inference. They make long-context generation feasible, reduce re-computation, and unlock interactive chat experiences. However, for long-running sessions like chatbots, agents, or copilots that persist for hours or days, KV cache eviction becomes inevitable.
Benchmarks demonstrate the severity: inference latency grows only linearly with sequence length (~2× from 128 to 2048 tokens) when utilizing a global KV cache, compared to exponential latency increases without caching. This difference translates directly to infrastructure costs and user experience.
Key takeaway: Memory optimization is not optional for production LLM applications; it determines whether your AI agents remain economically viable at scale.
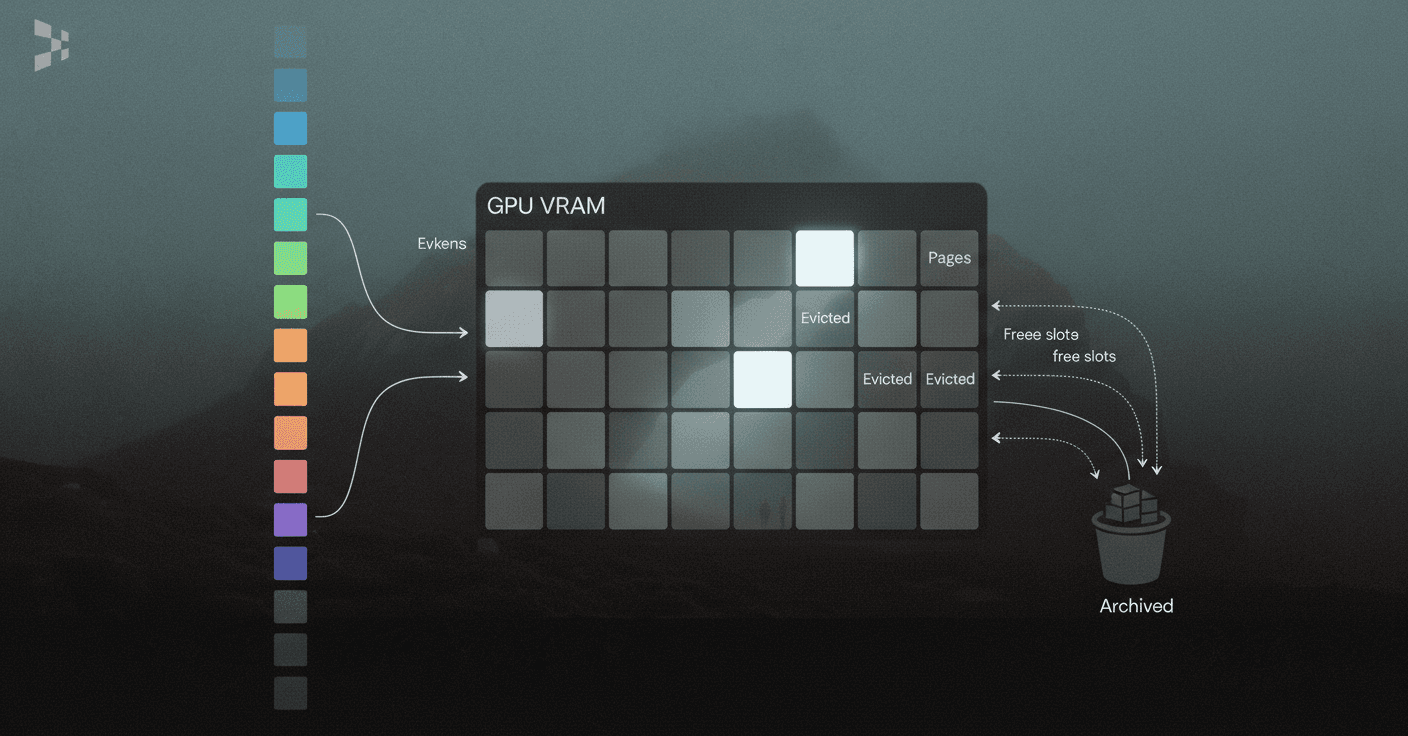
How Can You Optimize the KV Cache: Paging, Pruning & Eviction?
KV caching significantly improves the efficiency of LLM inference by storing attention states from previously processed tokens. However, existing systems struggle because the KV cache memory for each request is huge and grows and shrinks dynamically. Modern optimization approaches fall into three categories: paging, pruning, and intelligent eviction.
vLLM, an LLM serving system, achieves near-zero waste in KV cache memory and flexible sharing of KV cache within and across requests to further reduce memory usage. The system improves throughput by 2-4× with the same level of latency compared to state-of-the-art systems like FasterTransformer and Orca.
PagedEviction represents a novel fine-grained, structured KV cache pruning strategy that enhances memory efficiency. By introducing an efficient block-wise eviction algorithm tailored for paged memory layouts, it achieves better accuracy than baselines on long-context tasks while reducing memory consumption.
Research findings show that sub-O(n) memory methods suffer in multi-turn scenarios, while sparse encoding with O(n) memory and sub-O(n²) pre-filling computation perform robustly. Dynamic sparsity yields more expressive KV caches than static patterns, making it the preferred approach for production workloads.
PagedAttention & vLLM
PagedAttention is an attention algorithm inspired by virtual memory and paging techniques from operating systems. Rather than allocating contiguous memory blocks for each request's KV cache, it manages memory in fixed-size pages that can be allocated and freed dynamically.
The practical benefits are substantial. Benchmarks on an NVIDIA L4 GPU (24GB) demonstrate that PagedAttention causes minimal incremental memory usage, observable only at sequence lengths exceeding 2048 tokens due to its power-of-two cache allocations. This approach significantly improves inference efficiency by minimizing redundant computations through effective use of cached KV tensors.
Adaptive Eviction: SAGE-KV, Lethe, FlexiCache
When memory budgets are tight, adaptive eviction policies determine which cached tokens to retain. Several approaches have emerged:
SAGE-KV: Achieves 4x higher memory efficiency with improved accuracy over static methods like StreamLLM, and 2x higher efficiency than dynamic methods like Quest
Lethe: Performs layerwise sparsity-aware allocation, assigning token pruning budgets based on estimated attention redundancy, achieving up to 2.56x throughput increase
FlexiCache: Reduces GPU memory footprint by up to 70%, improves offline serving throughput by 1.38-1.55x, and lowers online token latency by 1.6-2.1x
The key insight is that evicting KV entries is not equivalent to truncating text. LRU-style eviction risks deleting low-frequency, high-impact tokens, while FIFO assumes recency equals importance, which is often false. A more principled approach uses aggregate attention scores to guide eviction decisions.
Which Prompt Compression Techniques Shrink Costs Most?
Prompt compression offers a complementary approach to KV cache optimization by reducing the number of tokens that need processing in the first place. This technique proves particularly valuable for RAG applications where retrieved context can be lengthy.
LLMLingua-2 focuses on task-agnostic prompt compression for better generalizability. The approach uses data distillation to derive knowledge from LLMs, compressing prompts without losing crucial information. By formulating compression as a token classification problem using a Transformer encoder, it ensures faithfulness of compressed outputs.
The performance gains are significant. LLMLingua-2 is 3x-6x faster than existing prompt compression methods, while accelerating end-to-end latency by 1.6x-2.9x with compression ratios of 2x-5x. This speed improvement makes it practical for real-time applications.
LLMLingua & LongLLMLingua
The original LLMLingua demonstrated that aggressive compression is achievable without sacrificing quality. Within GSM8K benchmarks, LLMLingua retained reasoning capabilities at a 20x compression ratio with only 1.5% performance loss. The method achieves practical acceleration between 1.7x and 5.7x depending on the use case.
LLMLingua has been integrated into popular RAG frameworks including LangChain and LlamaIndex, making adoption straightforward. It can be used for KV cache compression as well, improving decoding speed alongside prompt reduction.
REFORM & SimpleMem for Million-Token Streams
For extreme context lengths, specialized frameworks become necessary. REFORM is a novel inference framework that efficiently handles long contexts through a two-phase approach involving incremental chunk processing and selective KV cache recomputation.
Compared to baselines, REFORM achieves over 52% and 34% performance gains on RULER and BABILong respectively at 1M context length. Critically, it reduces inference time by 30% and peak memory usage by 5%, demonstrating that efficiency and performance can improve simultaneously.
Beyond the Prompt: Episodic & Graph-Based Memory Layers
KV cache optimization and prompt compression address in-context efficiency, but production AI agents often need memory that persists across sessions. Episodic memory and graph-based architectures provide this capability while potentially reducing per-request costs.
Memory-augmented approaches reduce token usage by over 90% while maintaining competitive accuracy. This dramatic reduction comes from intelligently storing and retrieving relevant context rather than including everything in each prompt. Additionally, episodic memory can help LLMs recognize the limits of their own knowledge, improving response quality.
The architectural insight is that memory complexity should scale with model capability. Foundation models benefit most from RAG, while stronger instruction-tuned models gain from episodic learning through reflections and more complex agentic semantic memory.
Hindsight, a memory architecture treating agent memory as a structured substrate, demonstrates the potential. With an open-source 20B model, it lifts overall accuracy from 39% to 83.6% over a full-context baseline, outperforming full context GPT-4o. Scaling further pushes accuracy to 91.4% on LongMemEval benchmarks.
Continuum Memory vs RAG
Retrieval-augmented generation has become the default strategy for providing LLM agents with contextual knowledge. However, RAG has fundamental limitations: it treats memory as a stateless lookup table where information persists indefinitely, retrieval is read-only, and temporal continuity is absent.
For long-horizon agents, these limitations become problematic. The Continuum Memory Architecture (CMA) addresses this by maintaining and updating internal state across interactions through persistent storage, selective retention, associative routing, temporal chaining, and consolidation into higher-order abstractions.
"RAG treats memory as a stateless lookup table: information persists indefinitely, retrieval is read-only, and temporal continuity is absent," as noted in research on memory architectures. CMA represents a necessary architectural primitive for long-horizon agents, though challenges around latency, drift, and interpretability remain active areas of development.
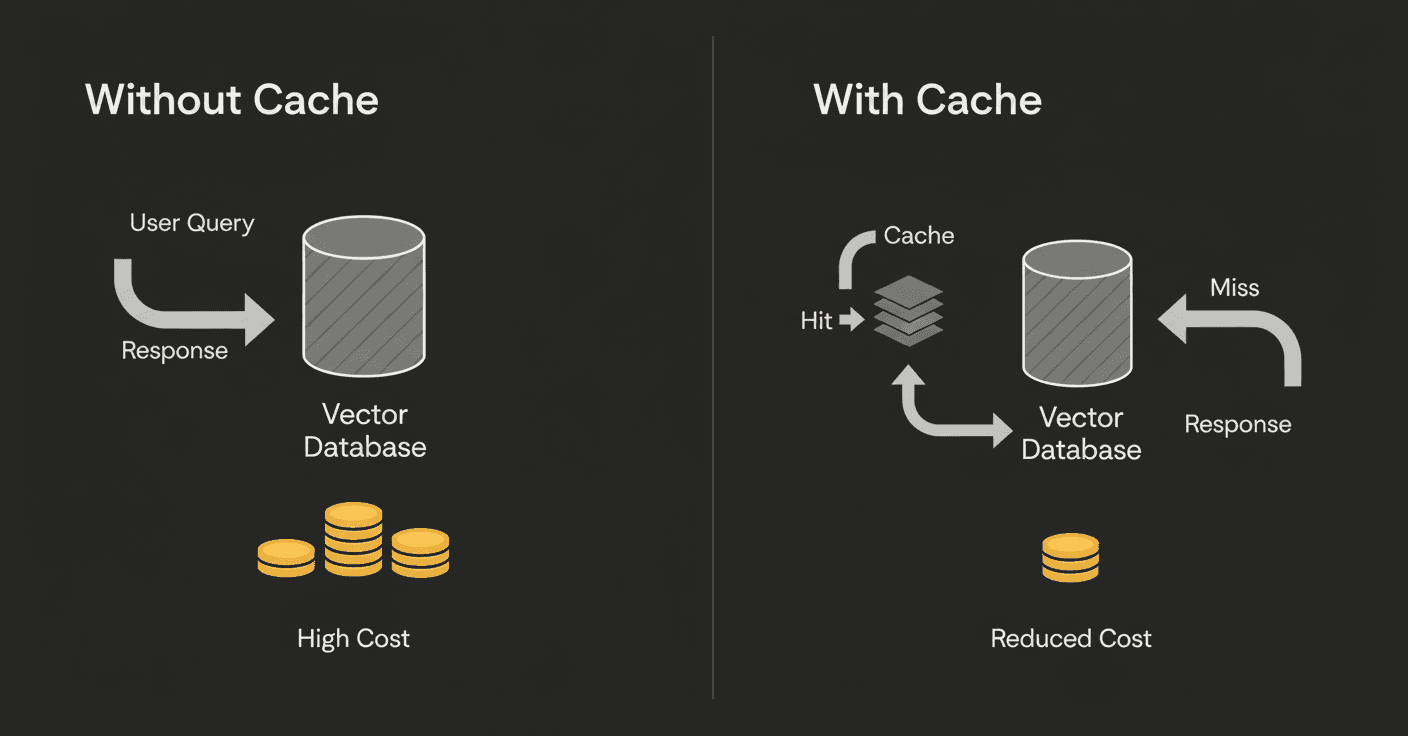
How Do Vector DB Costs Compare & When Does Semantic Caching Pay Off?
Vector databases form the retrieval backbone for most production RAG systems, and their costs vary dramatically based on architecture and scale. The vector database market has matured to $2.65 billion in 2025, projected to reach $8.95 billion by 2030 at a 27.5% CAGR.
Choosing the wrong platform can cost enterprises $500K+ annually in unnecessary infrastructure spend and 6-12 months of engineering rework. Understanding the trade-offs helps teams avoid expensive mistakes.
Redis LangCache is a fully-managed semantic caching service that reduces LLM costs and improves response times. LangCache uses semantic caching to store and reuse previous LLM responses for repeated queries, with benefits including advanced cache management, simpler deployments, faster AI app responses, and lower LLM costs.
Pinecone vs Weaviate vs Qdrant
Each platform offers distinct advantages for different use cases:
Feature | Pinecone | Weaviate | Qdrant |
|---|---|---|---|
Deployment | Managed SaaS | Self-host or Cloud | Self-host or Cloud |
P99 Latency | 40-50ms | 50-70ms | 30-40ms |
Storage Cost | $0.33/GB/month | ~$0.095 per 1M vector dimensions | Free tier + usage-based |
Best For | Startups, rapid deployment | RAG agents, hybrid search | High-throughput on-premises |
For datasets under 50 million vectors, managed SaaS solutions are drastically cheaper than self-hosting due to hidden DevOps costs. A cost simulation for storing 10 million vectors (1536 dimensions) shows Pinecone at ~$64/month, Weaviate at ~$85/month, and Milvus/Zilliz at ~$660/month.
Cut Re-query Bills with Semantic Caching
Semantic caching delivers outsized returns for applications with repetitive queries. According to Amit Lamba, CEO of Mangoes.ai: "Our voice app for patient care gets a lot of specific treatment questions, so it has to be absolutely accurate. I was worried about LLM costs for high usage, but with LangCache, we're getting a 70% cache hit rate, which saves 70% of our LLM spend. On top of that, it's 4X faster, which makes a huge difference for real-time patient interactions."
The rule of thumb: when duplicate or semantically similar queries exceed 25%, deploying an embedding-level cache beats scaling the database. LangCache claims up to 90% savings on API costs for applications with high query repetition.
Training-Time Memory Hacks: LoRA, Quantization & ZeRO
Inference optimization gets the most attention, but training-time memory reduction directly impacts development costs and iteration speed. Three techniques dominate: Low-Rank Adaptation (LoRA), quantization, and ZeRO offloading.
LoRA offers a cost-effective fine-tuning solution by freezing original model parameters and training only lightweight, low-rank adapter matrices. LoRAM extends this by training on a pruned model to obtain pruned low-rank matrices, which are then recovered for inference with the original large model.
The memory savings are dramatic. For a model with 70 billion parameters, LoRAM enables training on a GPU with only 20GB HBM, replacing an A100-80G GPU for LoRA training and 15 GPUs for full fine-tuning.
LORAQUANT pushes efficiency further through mixed-precision quantization. It achieves competitive performance even under ultra-low bitwidth for LoRA (less than 2 bits on average), making it particularly valuable when multiple LoRAs must be loaded simultaneously.
ZeRO-Offload complements these approaches by offloading optimizer memory and computation to the host CPU. This enables large models with up to 13 billion parameters to be trained efficiently on a single GPU. The DeepSpeedCPUAdam optimizer is 5-7x faster than standard PyTorch implementation, minimizing the performance penalty of CPU offloading.
System-Level Accelerators & Processing-in-Memory (PIM)
Beyond software optimization, hardware innovations are raising memory ceilings for LLM workloads. Processing-in-Memory and specialized accelerators address fundamental bottlenecks that software alone cannot solve.
Agentic LLM inference tasks are fundamentally different from chatbot-focused inference since they often require much larger context lengths to capture complex inputs like entire webpage DOMs or complicated tool call trajectories. This generates significant off-chip memory traffic, causing workloads to be constrained by bandwidth and capacity memory walls.
PLENA, a hardware-software co-designed system, tackles these walls with a flattened systolic array architecture featuring native FlashAttention support. Simulated results show PLENA achieves up to 8.5x higher utilization than existing accelerators, delivering 2.24x higher throughput than A100 GPUs and 3.85x higher throughput than TPU v6e under equivalent settings.
The expansion of long-context LLMs creates significant memory system challenges that Processing-in-Memory systems can address. However, PIM suffers from critical inefficiencies when scaled: severe channel underutilization, I/O bottlenecks, and memory waste from static KV cache management.
PIMphony resolves these issues with three co-designed techniques, achieving performance boosts of up to 11.3x on PIM-only systems and 8.4x on xPU+PIM systems. These gains suggest that hybrid architectures will become increasingly important as context lengths continue to grow.
How to Match Memory Strategies to Your Budget
Selecting the right combination of techniques depends on your team size, workload characteristics, and budget constraints. Here's a practical checklist:
For Early-Stage Startups (< $5K/month infrastructure):
Start with Pinecone Serverless for zero fixed costs and scale-to-zero capability
Implement semantic caching early; even 25% query repetition justifies the investment
Use LLMLingua for prompt compression in RAG pipelines
Consider Qdrant's free tier for experimentation
For Growth-Stage Companies ($5K-50K/month):
Evaluate hybrid search requirements; Weaviate offers superior hybrid search for fetching accurate context
Deploy vLLM with PagedAttention for inference serving
Implement adaptive KV cache eviction (SAGE-KV or Lethe)
Add episodic memory for multi-session agents
For Enterprise Teams (>$50K/month):
Self-host vector databases when exceeding 50M vectors
Consider Processing-in-Memory accelerators for extreme context lengths
Deploy hierarchical caching with both semantic and KV cache layers
Implement Continuum Memory Architecture for long-horizon agents
Memory architecture complexity should scale with model capability. Foundation models benefit most from RAG, while stronger instruction-tuned models gain from episodic learning and more complex agentic semantic memory. The 70% cache hit rates achievable with semantic caching represent easy wins before investing in more sophisticated approaches.
Key Takeaways
Cost-efficient memory expansion requires a layered approach matching techniques to specific bottlenecks:
KV cache optimization delivers immediate gains through paging (2-4x throughput), pruning (up to 70% memory reduction), and adaptive eviction (2.56x throughput increase)
Prompt compression reduces input costs by 20x with minimal performance loss, integrating seamlessly with existing RAG frameworks
Episodic memory layers cut token usage by over 90% while improving accuracy for multi-session agents
Vector database selection can mean the difference between $64/month and $660/month for the same workload
Training-time optimizations like LoRA and ZeRO enable 70B parameter training on 20GB GPUs
For teams building production AI agents where accuracy, latency, and long-term learning matter, platforms like Cortex combine enterprise data, context-aware knowledge graphs, and built-in memory into a single retrieval and memory platform. Rather than assembling fragmented stacks of vector databases, embedding pipelines, and memory systems, such integrated approaches eliminate the infrastructure complexity while delivering memory-augmented retrieval that actually works in production.
The most effective strategy combines multiple techniques: start with KV cache optimization for immediate wins, add prompt compression for RAG workloads, implement semantic caching for repetitive queries, and graduate to episodic memory as your agents require multi-session continuity. Each layer compounds savings while improving the quality of AI responses.
Frequently Asked Questions
Why is memory expansion important for production LLMs?
Memory expansion is crucial for production LLMs because it addresses efficiency challenges during long-context inference, which can lead to increased GPU memory usage and higher infrastructure costs. Optimizing memory ensures AI agents remain economically viable at scale.
What are some effective KV cache optimization techniques?
Effective KV cache optimization techniques include paging, pruning, and adaptive eviction. These methods help manage memory usage by storing attention states efficiently, reducing memory consumption, and improving throughput without compromising accuracy.
How does prompt compression benefit LLM applications?
Prompt compression reduces the number of tokens processed, lowering input costs and improving efficiency. Techniques like LLMLingua-2 offer significant speed improvements, making them practical for real-time applications by compressing prompts without losing crucial information.
What role does episodic memory play in AI agents?
Episodic memory allows AI agents to maintain continuity across sessions, reducing token usage and improving accuracy. It provides persistent memory that helps agents recognize knowledge limits and enhances response quality, especially in multi-session environments.
How does Cortex enhance memory management for AI applications?
Cortex enhances memory management by integrating enterprise data, context-aware knowledge graphs, and built-in memory into a single platform. This approach eliminates the need for fragmented stacks, providing a self-improving retrieval and memory layer that adapts to data and user behavior.