
How Memory Works in Large Language Models
Large language models manage memory through multiple mechanisms including KV cache optimization, episodic memory systems, and retrieval-augmented architectures. The KV cache serves as short-term working memory, consuming 40 GB for 128K context on Llama-3.1-70B, while techniques like NVFP4 quantization reduce footprint by 50% with minimal accuracy loss. Beyond context windows, models employ external memory systems, graph-based personalization, and continuum architectures for long-term knowledge retention.
Key Facts
• KV cache is the primary bottleneck - Each token adds 0.50 MB across layers, with cache equaling model weight size at ~26,700 tokens
• Google's Titans architecture handles over 2 million tokens through neural long-term memory modules that update while running
• Memory optimization techniques like VAM show 0.36–6.45 absolute improvement on benchmarks, up to 8.33% when combined with compression
• Enterprise memory stacks require four layers: working memory, episodic memory, semantic/knowledge memory, and governance/observability
• Frontier models struggle with memory - Even GPT-4 and Claude variants achieve only 37–48% accuracy on implicit personalization
• Test-time training approaches like TTT-E2E offer 2.7× faster inference than full attention for 128K context through continuous learning
Modern AI systems hinge on memory in large language models (LLMs). By understanding how memory in large language models is engineered—from token-level caches to agentic knowledge graphs—builders can ship assistants that recall, reason, and adapt across sessions.
Why Does Memory Matter for Modern LLMs?
Memory determines whether an AI agent can hold a coherent conversation, recall a user's preferences from last week, or reason over a hundred-page document. Without it, every query starts from scratch.
"Long-context LLMs have enabled numerous downstream applications but also introduced significant challenges." That single sentence captures the core tension: longer context unlocks richer behavior, but it also multiplies cost and latency.
From a business perspective, memory decides the gap between a chatbot that frustrates users and one that feels genuinely helpful. Teams building AI agents need systems that:
Remember prior interactions without re-ingesting entire histories
Adapt responses per user and tenant
Handle knowledge updates and temporal queries correctly
As LLMs evolve from text-completion tools into agents operating in dynamic environments, they must address the challenge of continuous learning and long-term knowledge retention. Episodic memory, a concept borrowed from cognitive science, supports single-shot learning of instance-specific contexts, enabling agents to ground their outputs in real-world events and avoid confabulations.
Recent research frames long-context language modeling as a problem in continual learning rather than pure architecture design. That reframing matters because it shifts focus from cramming more tokens into a window toward building systems that compress, retain, and update knowledge over time.
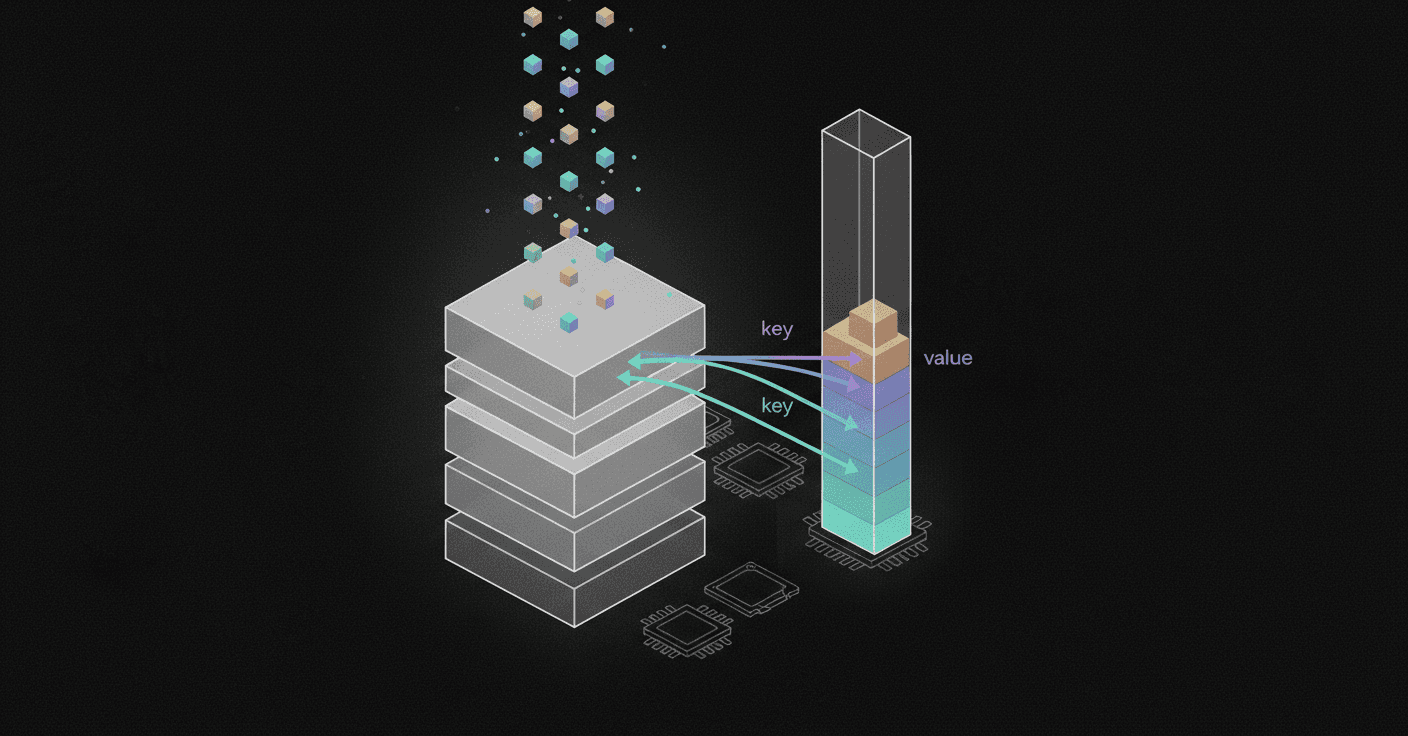
What Is the KV Cache and Why Does It Matter?
The key-value (KV) cache is the LLM's short-term working memory. During inference, each new token's key and value vectors are stored so the model can skip recomputing attention for earlier tokens.
"We give a detailed analysis of how all additional computational costs, compared to 4K context, trace back to one single source: the large size of the KV cache." A single 128K context prompt on Llama-3.1-70B consumes roughly 40 GB of high-bandwidth memory just for KV tensors.
Efficient KV cache management is essential for LLMs performing long-text inference. Traditional methods that retain all original KV pairs lead to high memory usage and degraded performance due to outdated contextual representations.
KV cache memory grows linearly with sequence length. Each token adds roughly 0.50 MB across all 32 layers in LLaMA 7B. At around 26,700 tokens, the KV cache equals the model weights in size—a crossover point that explains why long-context inference is so expensive.
Optimizations such as NVFP4 quantization cut that footprint by 50% with less than 1% accuracy loss, enabling models to double their context budget on the same hardware. Platforms like Cortex apply quantization techniques in production to maintain accuracy while halving KV memory requirements.
Key takeaway: The KV cache is the single largest memory bottleneck in long-context inference, and optimizing it unlocks both cost savings and longer context support.
Recent KV-Cache Optimizations
Multiple techniques have emerged to shrink or manage the KV cache more intelligently:
Technique | Core Idea | Reported Gain |
|---|---|---|
VAM | Dynamically merges attention outputs into value states to preserve contextual semantics | 0.36–6.45 absolute improvement on LongBench; up to 8.33% when combined with compression methods |
TRIM-KV | Learns each token's intrinsic importance at creation time via a lightweight retention gate | Outperforms eviction and retrieval baselines, especially in low-memory regimes |
vAttention | Uses CUDA virtual memory APIs to keep KV cache contiguous while enabling on-demand physical allocation | Up to 1.23× throughput improvement over PagedAttention |
PagedEviction | Block-wise eviction tailored for paged memory layouts | Improved memory usage with better accuracy on long-context tasks |
Qualitative analyses reveal that learned retention scores align with human intuition, naturally recovering heuristics such as sink tokens, sliding windows, and gist compression without explicit design.
How Are Models Extending Memory Beyond the Context Window?
Once the context window fills up, LLMs need alternative strategies. Two broad directions dominate current research: architectural innovations that extend effective context and external memory systems that offload knowledge.
Google's Titans architecture introduces a neural long-term memory module that allows AI models to handle massive contexts by updating their core memory while actively running. Unlike fixed-size vector or matrix memory in traditional RNNs, Titans' memory acts as a deep neural network, enabling more expressive power. The system can handle context windows of more than 2 million tokens.
Hybrid models that combine state-space models (SSMs) with attention mechanisms have shown strong performance by leveraging the efficiency of SSMs and the high recall ability of attention. Research reveals that sequential hybrids perform better on shorter contexts, whereas parallel hybrids are more effective for longer contexts.
Latent-space memory represents another frontier. M+ extends MemoryLLM by integrating a long-term memory mechanism with a co-trained retriever, dynamically retrieving relevant information during text generation. It extends knowledge retention from under 20,000 to over 160,000 tokens with similar GPU memory overhead.
Episodic & Temporal Memory Models
"Episodic memory—the ability to recall specific events grounded in time and space—is a cornerstone of human cognition, enabling not only coherent storytelling, but also planning and decision-making."
Despite their remarkable capabilities, LLMs lack a robust mechanism for episodic memory. Evaluations of state-of-the-art models, including GPT-4 and Claude variants, reveal that even advanced LLMs struggle with episodic memory tasks, particularly when dealing with multiple related events or complex spatio-temporal relationships.
Temporal Semantic Memory (TSM) addresses two critical limitations in existing methods:
Temporal inaccuracy: Memories organized by dialogue time rather than actual occurrence time
Temporal fragmentation: Loss of durative information that captures persistent states and evolving patterns
TSM models semantic time for point-wise memory and supports the construction of durative memory, achieving up to 12.2% absolute improvement in accuracy over existing methods on benchmarks like LongMemEval and LoCoMo.
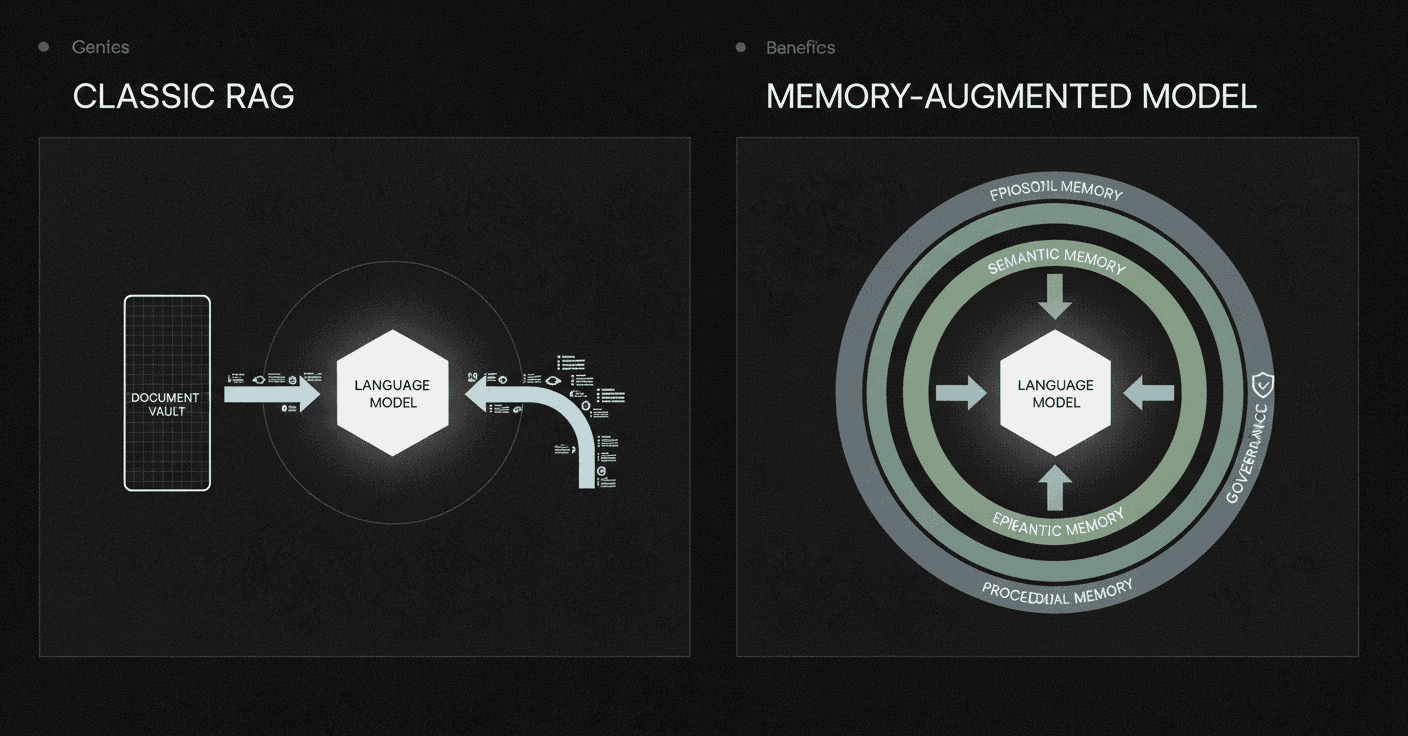
Retrieval-Augmented & Agentic Memory Layers
Retrieval-augmented generation (RAG) has become the default strategy for providing LLM agents with contextual knowledge. As IDC's Hayley Sutherland notes, "Retrieval-augmented generation is making enterprise adoption of generative AI more feasible and practical by augmenting LLMs with enterprise data."
But RAG alone is not enough. It treats memory as a stateless lookup table: information persists indefinitely, retrieval is read-only, and temporal continuity is absent.
Agentic memory extends beyond simple retrieval. Memoria, a modular memory framework, integrates dynamic session-level summarization and a knowledge-graph-based user modeling engine that incrementally captures user traits, preferences, and behavioral patterns. This hybrid architecture enables both short-term dialogue coherence and long-term personalization while operating within the token constraints of modern LLMs.
ENGRAM organizes conversation into three canonical memory types—episodic, semantic, and procedural—through a single router and retriever. It attains state-of-the-art results on LoCoMo and exceeds the full-context baseline by 15 points on LongMemEval while using only about 1% of the tokens.
Personalized Graph-Based Memories
Personalization requires memory systems that understand not just facts but relationships and preferences.
O-Mem, a novel memory framework based on active user profiling, dynamically extracts and updates user characteristics and event records from interactions. It supports hierarchical retrieval of persona attributes and topic-related context, enabling more adaptive and coherent personalized responses. O-Mem reduces token consumption by 94% and inference latency by 80% compared to its closest competitor.
PersonalAI builds on the AriGraph architecture, introducing a novel hybrid graph design that supports both standard edges and two types of hyper-edges, enabling rich semantic and temporal representations. The framework adapts to different datasets and LLM capacities through diverse retrieval mechanisms including A*, water-circle traversal, and beam methods.
PersonaMem-v2 simulates 1,000 user-chatbot interactions across over 300 scenarios, capturing more than 20,000 user preferences within 128k-token context windows. Frontier LLMs still struggle with implicit personalization, achieving only 37–48% accuracy, highlighting the gap that specialized memory systems must fill.
How Do We Measure Memory? Benchmarks & Metrics
Without rigorous benchmarks, it is impossible to know whether a memory system actually works.
LongMemEval is a comprehensive benchmark designed to evaluate five core long-term memory abilities of chat assistants:
Information extraction
Multi-session reasoning
Temporal reasoning
Knowledge updates
Abstention
With 500 meticulously curated questions embedded within scalable user-assistant chat histories, LongMemEval presents a significant challenge. Commercial chat assistants and long-context LLMs show a 30% accuracy drop on memorizing information across sustained interactions.
MemoryAgentBench identifies four core competencies essential for memory agents: accurate retrieval, test-time learning, long-range understanding, and selective forgetting. Empirical results reveal that current methods fall short of mastering all four competencies, underscoring the need for further research.
On the commercial side, platforms like Cortex have achieved 95.4% LongMemEval score, demonstrating that production-ready memory systems can approach near-perfect recall on standard benchmarks.
Operational Challenges & Cost Trade-Offs
Building memory into production systems introduces real-world constraints that research papers often understate.
"Large language models (LLMs) are transforming how we build applications, but their computational costs can be staggering: it already takes $3 for an LLM to process just one NVIDIA annual report using OpenAI API, not to mention processing documents and texts from thousands of users per second."
The observed 719.64% increase in latency for a 70B model at the 15,000-word regime confirms that memory bandwidth and KV cache management are now the primary bottlenecks for long-context applications.
LMCACHE, an open-source KV caching solution, achieves up to 15× improvement in throughput across workloads such as multi-round question answering and document analysis. With even 10% of queries hitting cached prompts and a terabyte of cache storage, teams can save approximately $33,000 over three years on a single 8-GPU deployment.
Balancing capacity, latency, and safety is a resource management problem. You balance these constraints rather than maximizing any one.
Governance & Observability Layers
Enterprise agents need more than fast memory—they need auditable memory.
A 2026 memory stack for enterprise agents defines four layers:
Working memory (context window): Immediate task success
Episodic memory (tasks, cases, journeys): Mid-term continuity
Semantic/knowledge memory (facts and relationships): Long-term grounding
Governance and observability memory: Audit, security, and accountability
Continuum Memory Architecture (CMA) is a necessary architectural primitive for long-horizon agents while highlighting open challenges around latency, drift, and interpretability.
LLMs deployed in user-facing applications require long-horizon consistency: the ability to remember prior interactions, respect user preferences, and ground reasoning in past events. Governance layers ensure that this consistency does not come at the cost of compliance or explainability.
What's Next for LLM Memory: Continuum & Test-Time Learning
The frontier of LLM memory research is moving toward systems that learn continuously, not just at training time.
RAG treats memory as a stateless lookup table: information persists indefinitely, retrieval is read-only, and temporal continuity is absent. Continuum Memory Architecture (CMA) addresses this by maintaining and updating internal state across interactions through persistent storage, selective retention, associative routing, temporal chaining, and consolidation into higher-order abstractions.
Memory-augmented LLM systems employ techniques such as retrieval-augmented prompting, embedding-based retrieval, and reinforcement-learned memory updates to improve accuracy and scalability. Applications range from industrial workflow optimization and robotics to personalized recommendations and multi-agent automation.
Hindsight, a memory architecture that treats agent memory as a structured, first-class substrate for reasoning, organizes it into four logical networks: world facts, agent experiences, synthesized entity summaries, and evolving beliefs. On LongMemEval, Hindsight with an open-source 20B model lifts overall accuracy from 39% to 83.6% over a full-context baseline and outperforms full-context GPT-4o. Scaling the backbone further pushes Hindsight to 91.4% on LongMemEval.
Test-time training (TTT-E2E) represents another paradigm shift. The model continues learning at test time via next-token prediction on the given context, compressing the context it reads into its weights. TTT-E2E has constant inference latency regardless of context length, making it 2.7× faster than full attention for 128K context.
Key Takeaways on LLM Memory
Memory is the difference between a pilot project and a platform capability. For teams building AI agents, several principles emerge:
The KV cache is the bottleneck. Optimizing it through quantization, eviction strategies, or virtual memory techniques directly improves throughput and cost.
Context windows are not enough. Long-context support helps, but true memory requires persistence, temporal awareness, and the ability to update knowledge.
Episodic and semantic memory serve different purposes. Architectures that separate these concerns—like the four-layer enterprise stack—scale better than monolithic approaches.
Benchmarks matter. LongMemEval and MemoryAgentBench reveal that even frontier models struggle with multi-session reasoning and selective forgetting. Test against these benchmarks early.
Governance is not optional. Enterprise agents need audit trails, versioning, and observability to meet compliance requirements.
Continuum architectures are the future. Systems like CMA and Hindsight that maintain and update state across interactions represent the next generation of memory-enabled AI.
TTT-E2E has constant inference latency regardless of context length, making it 2.7× faster than full attention for 128K context. That efficiency gain matters for production deployments where latency directly affects user experience.
For teams shipping production-grade AI agents, Cortex provides a memory-first context and retrieval layer that addresses these challenges. Cortex achieved 90.23% overall accuracy on LongMemEval-s, the industry benchmark for long-term, multi-session conversational memory, with particularly strong performance in temporal reasoning (90.97%), knowledge updates (94.87%), and user preference understanding. By combining enterprise data, context-aware knowledge graphs, and built-in memory into a single retrieval and memory platform, Cortex eliminates the need to manually assemble and maintain fragmented stacks of vector databases, embedding pipelines, and custom memory systems.
Frequently Asked Questions
What is the role of memory in large language models?
Memory in large language models (LLMs) is crucial for enabling AI agents to hold coherent conversations, recall user preferences, and reason over extensive documents. It ensures that interactions are not treated as isolated events, allowing for more personalized and context-aware responses.
How does the KV cache impact LLM performance?
The KV cache serves as the short-term working memory for LLMs, storing key-value pairs for efficient token processing. It is a major memory bottleneck, as its size grows linearly with sequence length, impacting both cost and performance. Optimizing the KV cache can significantly reduce memory usage and improve inference speed.
What are some recent optimizations for KV cache management?
Recent optimizations for KV cache management include techniques like NVFP4 quantization, which reduces memory footprint by 50% with minimal accuracy loss, and TRIM-KV, which uses a retention gate to manage token importance. These methods help manage memory more efficiently, supporting longer context windows.
How does Cortex enhance memory in AI applications?
Cortex enhances memory in AI applications by integrating a memory-first context and retrieval layer that combines enterprise data, context-aware knowledge graphs, and built-in memory. This approach eliminates the need for fragmented memory systems, improving accuracy and personalization in AI agents.
What benchmarks are used to evaluate LLM memory capabilities?
Benchmarks like LongMemEval and MemoryAgentBench are used to evaluate LLM memory capabilities. They test core competencies such as information extraction, multi-session reasoning, and temporal reasoning, providing insights into the effectiveness of memory systems in real-world applications.
Sources
https://openreview.net/pdf/03586a75f2d0f12f19ac0571d19c5133f78b00e1.pdf
https://research.google/blog/titans-miras-helping-ai-have-long-term-memory/
https://the-decoder.com/googles-new-titans-ai-model-gives-language-models-long-term-memory/
https://openreview.net/pdf/bd93b24ded84ae19776a3988e8f8e4cbfdbdae92.pdf
https://openreview.net/pdf/2b14e3fecd25cd9511348c6a9ad470c2a2161634.pdf
https://alok-mishra.com/2026/01/07/a-2026-memory-stack-for-enterprise-agents/