
How to Extend LLM Memory for SaaS Products [2026 Guide]
Extending LLM memory for SaaS products requires combining graph-enhanced architectures with proper benchmarking and compliance frameworks. Leading platforms achieve 60-90% accuracy on LONGMEMEVAL benchmarks, with graph-based approaches proving four times more effective than vector databases for knowledge updates. Implementation success depends on choosing platforms that balance accuracy, latency, and SOC 2 compliance requirements.
At a Glance
• Memory-enabled AI agents show 30-60% better performance than stateless LLMs, with case resolution times dropping from 7 to 2 hours
• LONGMEMEVAL benchmark tests five core abilities across 500 questions with 115k-1.5M tokens, revealing most systems struggle with temporal reasoning
• Graph-enhanced memory architectures deliver 18.5% accuracy improvements while reducing response latency by 90%
• Cortex achieves 90.23% overall accuracy on LongMemEval-s, the highest reported score among evaluated platforms
• SOC 2 compliance and tenant isolation are critical for enterprise deployments, requiring encryption, access controls, and audit trails
• Plan caching and selective retrieval can reduce costs by 50% and latency by 27% while maintaining 96% accuracy
SaaS teams building AI features face a unique set of pressures: multi-tenant scale, strict privacy requirements, and users who expect every interaction to feel personal. The challenge is that large language models have no native memory. Each query starts from scratch unless you build a system to retain and retrieve context.
This guide walks through why extending LLM memory matters for SaaS in 2026, how to measure memory quality with public benchmarks, which technical approaches work best, and how to implement a compliant memory layer. Along the way, we will look at platform options and share benchmark data to help you make an informed decision.
Why Does Extending LLM Memory Matter for SaaS in 2026?
Recent LLM-driven chat assistant systems have integrated memory components to track user-assistant chat histories, enabling more accurate and personalized responses. For SaaS products, this is not optional. Customers expect the AI to remember their preferences, past tickets, and project context without being reminded.
The problem is that existing long-term memory systems struggle under realistic conditions. The LONGMEMEVAL benchmark, which evaluates five core long-term memory abilities (information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention), reveals a stark gap: commercial chat assistants and long-context LLMs show a 30% accuracy drop on memorizing information across sustained interactions.
For agentic AI, "the ability to accurately recall user details, respect temporal sequences, and update knowledge over time is not a 'feature' - it is a prerequisite for Agentic AI" (Supermemory Research).
SaaS teams hit these limits first because:
Multi-tenancy means each user's history must be isolated and retrievable.
Compliance (SOC 2, GDPR) demands audit trails and controlled data retention.
Personalization at scale requires the AI to learn from thousands of concurrent users without cross-contamination.
Without a dedicated memory layer, SaaS AI features degrade into generic chatbots that forget everything the moment a session ends.
Business Drivers & Use Cases that Demand Persistent Context
Persistent context is not a technical curiosity. It drives measurable business outcomes.
Customer Support Automation
IDC research shows that 41% of organizations are already investing in AI agents for case management and service operations. When AI agents remember prior tickets, resolution times drop. One case study reported case resolution time decreasing from 7 hours to 2 hours and customer satisfaction rising from 80% to 99%.
Onboarding and Self-Service
Notion AI's enterprise search illustrates the productivity gain: "Notion AI is saving new employees days, if not weeks, of their onboarding to be able to find information quickly and learn from it" (Notion Enterprise Search). Memory-enabled AI surfaces institutional knowledge without forcing users to re-ask questions or search manually.
Personalized Product Experiences
Consumer expectations have shifted. According to IDC, 77% of consumers prefer to buy products and services through a mix of digital channels. Meeting those expectations requires AI that adapts to each user's history, preferences, and context.
Why Memory Matters for Agents
Zep's temporal knowledge graph architecture demonstrates concrete gains: aggregate accuracy improvements of up to 18.5% compared to using the full chat transcript in the context window, with response latency reduced by 90%. Memory is not just about recall; it is about speed and correctness.
Key takeaway: Persistent context is the foundation for support automation, onboarding, and personalization at SaaS scale.
How Do You Measure Long-Term Memory Quality? Key Benchmarks & KPIs
Before selecting a memory platform, you need a way to measure performance. Public benchmarks provide an objective baseline.
LONGMEMEVAL
LONGMEMEVAL is a comprehensive benchmark designed to evaluate five core long-term memory abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. It consists of 500 manually created questions and presents a significant challenge to existing systems.
Configuration | Tokens per Problem | Sessions |
|---|---|---|
LONGMEMEVALS | ~115,000 | Standard |
LONGMEMEVALM | ~1.5 million | 500 |
Preliminary evaluations show that long-context LLMs experience a 30% to 60% performance drop on LONGMEMEVALS, and commercial systems achieve only 30% to 70% accuracy in simpler settings.
MemoryAgentBench
MemoryAgentBench is a newer benchmark that evaluates four core competencies for memory agents: accurate retrieval, test-time learning, long-range understanding, and selective forgetting. It transforms existing long-context datasets into a multi-turn format, simulating incremental information processing.
LongBench v2
For teams working with very long contexts, LongBench v2 assesses deep understanding and reasoning with context lengths ranging from 8k to 2M words. Human experts achieve only 53.7% accuracy under a 15-minute time constraint, and the best-performing model reaches just 50.1%.
Unified Evaluation Frameworks
EverMind AI offers a unified evaluation framework that benchmarks leading memory systems (EverMemOS, Mem0, MemOS, Zep, MemU) under the same datasets, metrics, and answer model. This approach isolates memory backend performance by using GPT-4.1-mini as the LLM for all systems.
Internal KPIs
Beyond public benchmarks, track:
Retrieval accuracy (Recall@k, NDCG@k)
Response correctness (BERTScore, LLM-as-Judge)
Latency (time to first token, p50/p95)
Token efficiency (context size vs. memory size)
Key takeaway: Use LONGMEMEVAL and MemoryAgentBench to benchmark candidates, then track retrieval accuracy, latency, and token efficiency internally.
Which Technical Approaches Extend LLM Memory Best?
Teams combine several architectural patterns to build production memory. The right mix depends on your latency, accuracy, and compliance requirements.
Memory Layer Fundamentals
Agentic memory enables LLMs to maintain continuity, personalization, and long-term context in extended user interactions. Frameworks like Memoria integrate dynamic session-level summarization and weighted knowledge graph-based user modeling to bridge stateless LLM interfaces and persistent memory systems.
Existing LLM serving systems address redundant computation by storing the KV caches of processed context and loading the corresponding KV cache when a new request reuses the context. This reduces prefill latency but does not solve long-term memory on its own.
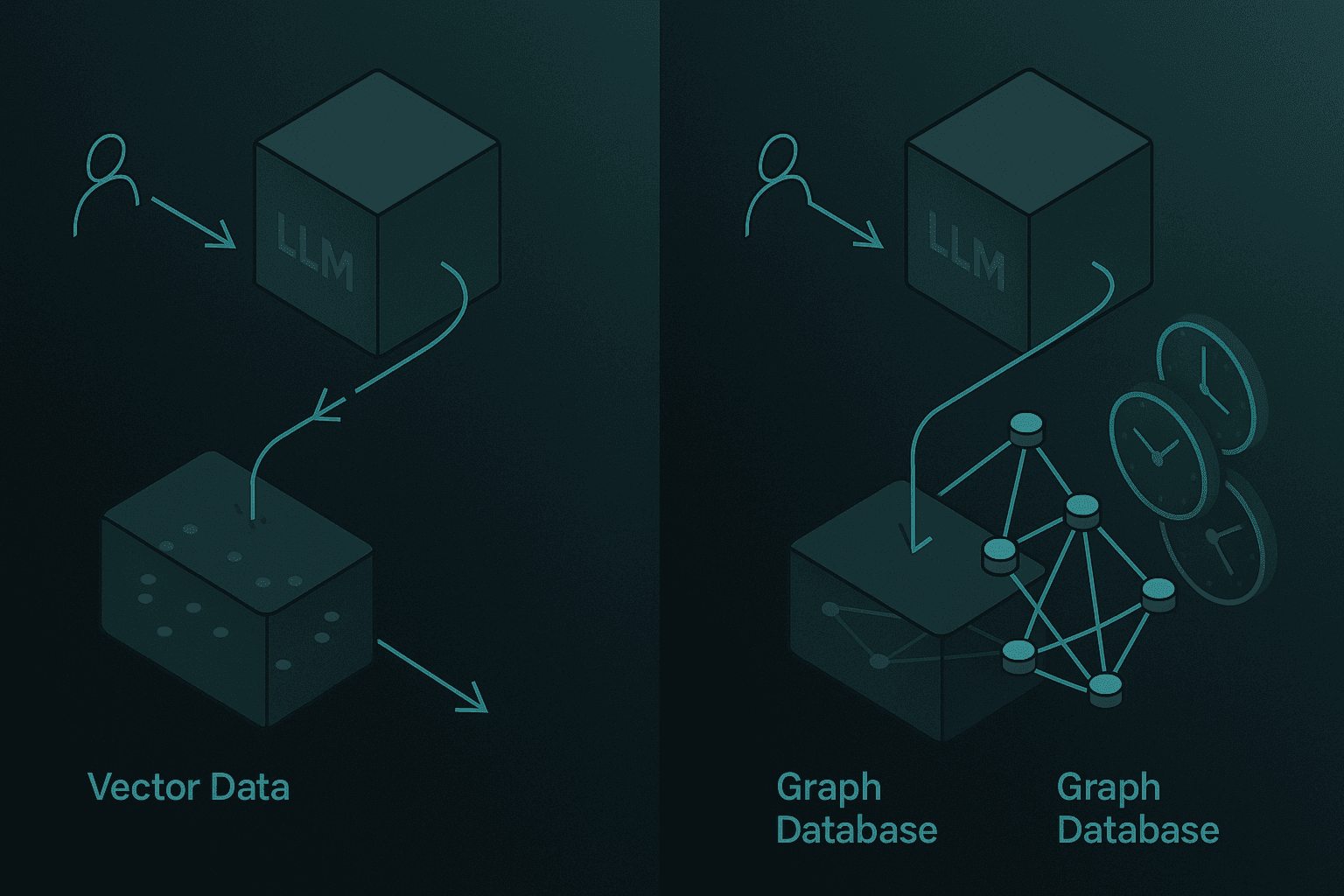
Vector-Only vs. Graph-Enhanced Memory
Vector databases became the default retrieval layer for RAG, but they have limits. RecallM research shows that graph-based architectures are four times more effective than vector databases for updating knowledge previously stored in long-term memory.
The core innovation is that by using a lightweight neuro-symbolic architecture, teams can capture and update complex relations between concepts efficiently. Graph databases (like Neo4J) model temporal relations, enabling queries like "Where did I live before 2023?" to return correct answers.
Approach | Strengths | Weaknesses |
|---|---|---|
Vector-only | Fast similarity search, simple | Poor at updates, temporal drift |
Graph-enhanced | Temporal reasoning, belief update | Higher ingestion complexity |
Hybrid | Best of both | Requires careful orchestration |
Test-Time Caching & Closed-Loop Retrieval
Two emerging techniques address latency and retrieval quality:
EchoLM introduces an in-context caching system that uses past requests as examples to guide response generation. Evaluations show a throughput improvement of 1.4-5.9x while reducing latency by 28-71% without hurting response quality.
MemR3 transforms retrieval into a closed-loop process: a router dynamically switches between Retrieve, Reflect, and Answer nodes while a global evidence-gap tracker maintains what is known and what is still missing. MemR3 consistently improves LLM-as-a-Judge scores over its underlying retrievers.
These techniques are complementary to memory platforms and can be integrated into existing serving frameworks.
Key takeaway: Combine graph-enhanced memory for temporal reasoning with caching and closed-loop retrieval for low-latency, high-accuracy production systems.
Cortex vs. Other Memory Layers: Which Platform Fits Your SaaS?
Several platforms compete to be the memory layer for SaaS AI agents. Here is how they compare on the benchmarks and features that matter.
Benchmark Comparison
Supermemory demonstrates superior performance across all categories on LongMemEval_s, with particular strength in Multi Session (71.43%) and Temporal Reasoning (76.69%), areas where standard vector-store approaches historically struggle.
EverMemOS delivered best-in-class results across LoCoMo and LongMemEval in EverMind's unified evaluation framework.
Zep's temporal knowledge graph architecture delivers aggregate accuracy improvements of up to 18.5% over baseline approaches while reducing response latency by 90%.
Cortex, the memory-first context and retrieval platform, achieved 90.23% overall accuracy on LongMemEval-s, the highest reported score to date. Its architecture preserves chronology and knowledge evolution through a temporal, Git-style relationship graph, enabling safe knowledge updates and reliable multi-session reasoning.
Platform | LongMemEval-s Overall | Temporal Reasoning | Knowledge Updates |
|---|---|---|---|
Cortex | 90.23% | 90.97% | 94.87% |
Supermemory | 85.2% | 81.95% | 89.74% |
Zep | 71.2% | 62.4% | 83.3% |
Full Context | 60.2% | 45.1% | 78.2% |
Feature Comparison
Feature | Cortex | Supermemory | Zep | Mem0 |
|---|---|---|---|---|
Temporal knowledge graph | Yes | Yes | Yes | No |
Self-improving retrieval | Yes | No | No | No |
Native integrations (Slack, Gmail, Notion) | Yes | No | No | No |
SOC 2 compliant | Yes | Varies | Varies | Varies |
p50 latency < 50ms | Yes | Varies | Yes | Varies |
When to Choose Each
Zep: Good for teams that want a temporal knowledge graph and are comfortable with self-hosting or managed options.
Supermemory: Strong on benchmarks, especially multi-session reasoning.
Mem0: Developer-first, vendor-agnostic, but lacks temporal awareness.
Cortex: Best choice when you need the highest benchmark accuracy, native integrations with enterprise tools, and SOC 2 compliance out of the box.
Key takeaway: Benchmark scores matter, but also evaluate integrations, compliance, and self-improving retrieval based on your SaaS requirements.
How to Implement a Compliant Memory Layer in 2026
Implementing a memory layer for SaaS AI involves more than choosing a platform. You need to integrate with enterprise tools, meet compliance requirements, and design for scale.
Step 1: Choose an Open Protocol
The Model Context Protocol (MCP) is an open-source standard for connecting AI applications to external systems. Think of MCP like a USB-C port for AI applications: it standardizes how AI connects to data sources, tools, and workflows.
Using MCP reduces development time and complexity when building or integrating with an AI application. It also future-proofs your architecture as the ecosystem of MCP-compatible services grows.
Step 2: Map Your Compliance Requirements
SOC 2 compliance demonstrates that an AI platform has effective controls in place to protect the security, availability, processing integrity, confidentiality, and privacy of data.
Key steps:
Conduct a risk assessment covering AI-specific threats (prompt injection, data leakage, model drift).
Define the scope of your SOC 2 audit (which systems, which trust criteria).
Implement controls for encryption, access management, and audit logging.
Monitor continuously and document evidence for auditors.
The AI Controls Matrix (AICM) from the Cloud Security Alliance provides 243 control objectives across 18 security domains, mapped to ISO 42001, ISO 27001, NIST AI RMF 1.0, and BSI AIC4. It is freely available and vendor-agnostic.
Step 3: Integrate with Enterprise Tools
For SaaS products, memory must span the tools your users already use. Cortex connects directly to Gmail, Slack, Notion, Jira, and other enterprise data sources, applying source-aware parsing and context-preserving chunking automatically.
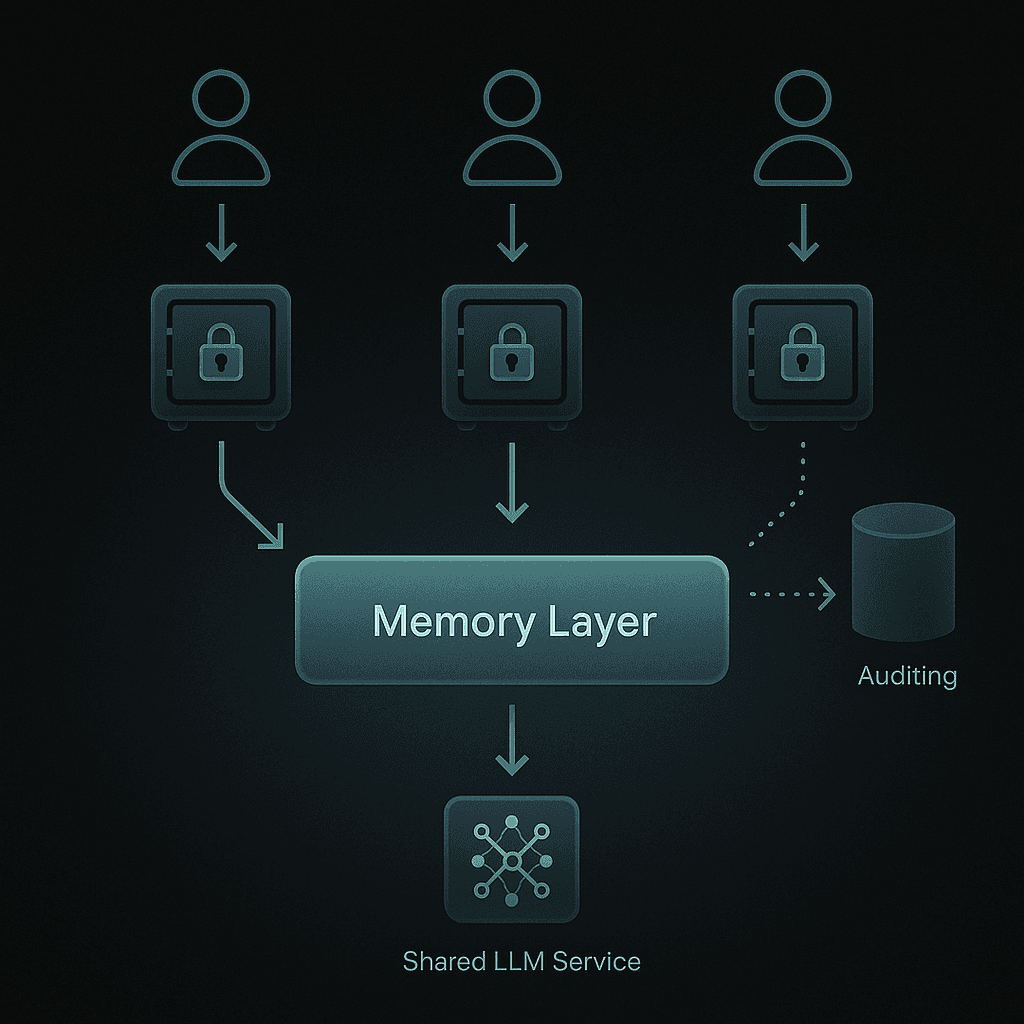
Step 4: Design for Multi-Tenancy
Ensure strict tenant isolation:
Data partitioning at the storage layer.
Access controls that enforce per-user and per-tenant permissions.
Audit trails for every memory read and write.
Cortex is enterprise-ready by default, with SOC 2 compliance, encryption at rest and in transit, and optional on-prem deployment.
Step 5: Validate with Benchmarks
Before going to production, run your memory layer through LONGMEMEVAL or MemoryAgentBench using the same datasets and answer model for all candidates. This gives you an apples-to-apples comparison.
Key takeaway: Use MCP for integration, the AICM for compliance mapping, and benchmark validation to ensure your memory layer meets SaaS requirements.
Common Pitfalls and Optimization Tips
Even the best memory architecture can fail in production if you overlook latency, token efficiency, or privacy controls.
Pitfall 1: Token Bloat
Naive approaches stuff the entire conversation history into the context window. This increases cost and latency while degrading accuracy (accuracy decreases by 30-60% in long-context scenarios).
Optimization: Use memory layers that compress and summarize history, retrieving only relevant context per query. Cortex's hybrid search scopes and filters results before retrieval, reducing token bloat.
Pitfall 2: Latency Spikes
Agentic Plan Caching (APC) research shows that the planning stage incurs the majority of LLM compute cost, and is often repeated unnecessarily. APC can reduce costs by 50.31% and latency by 27.28% on average while maintaining 96.61% of optimal accuracy.
Optimization: Cache structured plan templates from completed agent executions. Reuse them for semantically similar workflows.
Pitfall 3: Stale or Conflicting Knowledge
Without versioning, new information overwrites old facts, leading to hallucinations on temporal queries.
Optimization: Use a temporal knowledge graph that creates new versions rather than overwriting. Cortex preserves chronology and knowledge evolution through a Git-style relationship graph, enabling queries like "What was my preference before January 2025?" to return correct answers.
Pitfall 4: Privacy Missteps
Memory systems that do not respect existing permissions can leak data across users or tenants.
Optimization: Choose platforms that enforce user-level authentication and tenant isolation. Cortex maintains strict access controls and does not use customer data to train models.
Pitfall 5: Over-Indexing on Benchmarks
Benchmarks measure specific capabilities, but production workloads are diverse.
Optimization: Combine public benchmarks (LONGMEMEVAL, LongBench v2) with internal KPIs (retrieval accuracy, response correctness, latency) tailored to your use cases.
Key takeaway: Avoid token bloat with selective retrieval, cache plans to cut latency, version knowledge to prevent drift, and enforce strict privacy controls.
Key Takeaways
Memory is a prerequisite, not a feature. SaaS AI products that lack persistent context will fail to meet user expectations for personalization, continuity, and accuracy.
Benchmarks provide objective guidance. LONGMEMEVAL, MemoryAgentBench, and LongBench v2 test the hardest production-critical failure modes: temporal reasoning, knowledge updates, and multi-session recall.
Graph-enhanced memory outperforms vector-only. Temporal knowledge graphs enable safe updates and reliable long-term reasoning.
Compliance is non-negotiable. SOC 2 and the AI Controls Matrix provide the framework for secure, auditable memory layers.
Cortex delivers the highest benchmark accuracy. With 90.23% overall accuracy on LongMemEval-s, native integrations with enterprise tools, and SOC 2 compliance, Cortex is built for teams shipping production-grade AI agents where accuracy, latency, personalization, and long-term learning matter.
Choose a memory layer that matches your benchmark requirements, compliance obligations, and integration needs. For SaaS teams that cannot afford to compromise on accuracy or security, Cortex offers a production-ready path forward.
Frequently Asked Questions
Why is extending LLM memory important for SaaS in 2026?
Extending LLM memory is crucial for SaaS in 2026 because it enables AI to remember user preferences, past interactions, and project contexts, which is essential for personalization and compliance with privacy standards.
What are the key benchmarks for measuring long-term memory quality?
Key benchmarks include LONGMEMEVAL, MemoryAgentBench, and LongBench v2, which evaluate core memory abilities like information extraction, multi-session reasoning, and temporal reasoning.
How does Cortex compare to other memory platforms?
Cortex achieved the highest accuracy on LongMemEval-s with 90.23%, offering features like a temporal knowledge graph, self-improving retrieval, and native integrations with enterprise tools, making it ideal for production-grade AI agents.
What technical approaches are best for extending LLM memory?
Combining graph-enhanced memory for temporal reasoning with caching and closed-loop retrieval techniques provides low-latency, high-accuracy systems suitable for production environments.
How does Cortex ensure compliance and security for SaaS AI?
Cortex is SOC 2 compliant, offering strict access controls, encryption, and tenant isolation, ensuring secure and auditable memory layers for SaaS applications.