
Mem0 vs Cortex: Which Scales Better for Multi-Agent Systems?
When comparing Mem0 and Cortex for multi-agent systems, both platforms deliver significant token savings and sub-second latency, but Cortex edges ahead with 90.23% accuracy on LongMemEval-s benchmarks and its self-improving memory layer that provides 60-90% storage savings through fact extraction. The choice depends on your specific requirements: Mem0 excels in cost efficiency with proven 90% token reduction, while Cortex offers superior accuracy and enterprise-ready features for production deployments.
Key Facts
• Mem0 achieves 26% higher response accuracy than OpenAI's memory feature with 66.9% overall accuracy on LoCoMo benchmarks
• Cortex delivers 90.23% accuracy on LongMemEval-s, the highest reported score for long-term conversational memory
• Both platforms reduce token usage by 90%, with Mem0 averaging 7k tokens per conversation and Cortex achieving 99% reduction through fact extraction
• Mem0 maintains 0.20s median latency with 0.15s p95, while Cortex delivers sub-second response times at scale
• Research shows 95% of AI pilots fail without proper memory architecture for multi-agent coordination
• Emerging research like SwiftMem demonstrates 47x faster retrieval speeds, indicating future memory systems will need multi-dimensional indexing and selective forgetting capabilities
Choosing the right memory architecture can decide whether your multi-agent systems plateau or accelerate. This post compares Mem0 vs Cortex head-to-head so you can decide which platform scales better.
Why Memory Architecture Defines Multi-Agent Scale
Single-agent architectures often collapse under operational pressure. Research shows that "95% of AI pilots fail to reach production, not because the underlying models lack capability, but because single-agent architectures collapse under operational pressure."
Distributed multi-agent systems (DMAS) based on large language models enable collaborative intelligence while preserving data privacy. The memory layer becomes existential for these systems because agents must share context, track preferences across sessions, and reason over evolving knowledge.
Multi-agent systems solve reliability problems by distributing cognitive load across specialized agents, each handling a narrow domain with explicit state boundaries. Without persistent memory, these agents cannot coordinate effectively or maintain coherence across interactions.
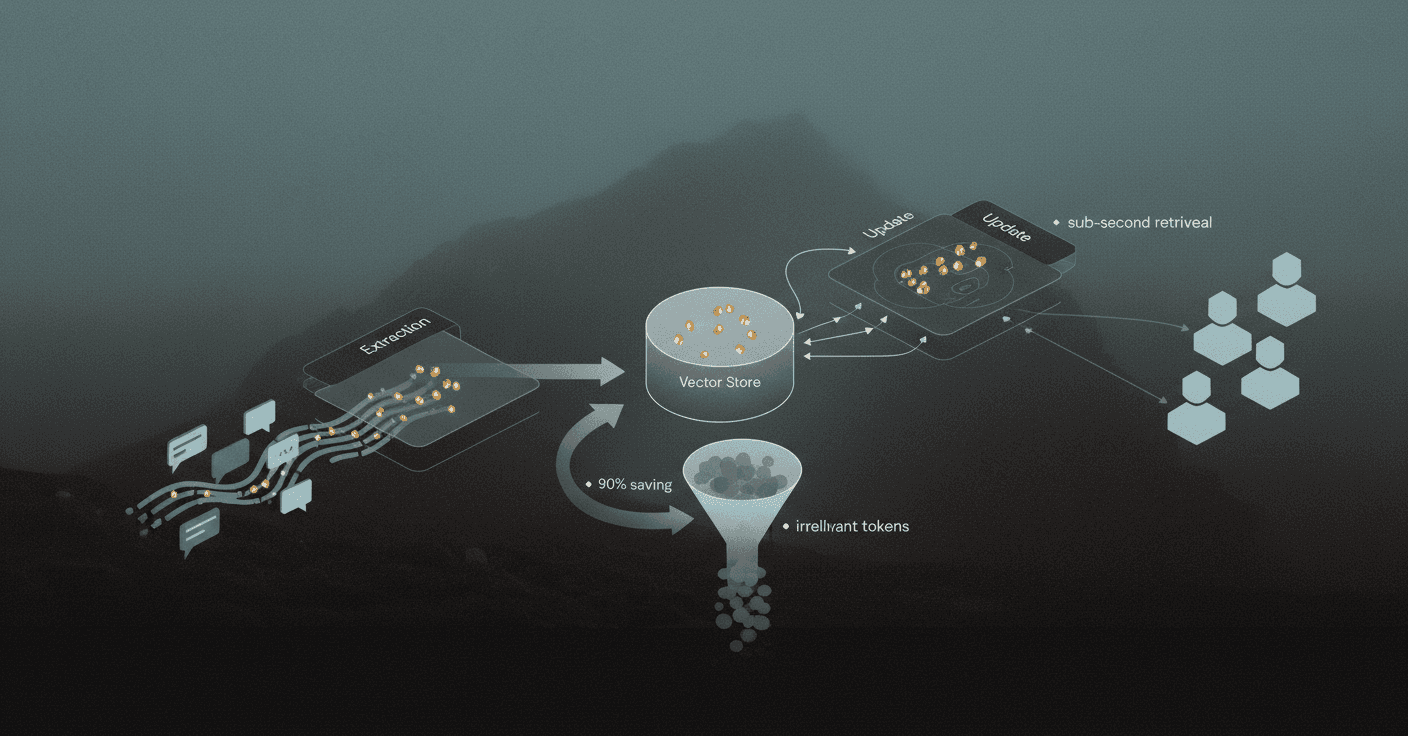
How Does Mem0 Handle Long-Term Memory at Scale?
Mem0 introduces a scalable memory-centric architecture that dynamically extracts, consolidates, and retrieves salient information from ongoing conversations. The system addresses fixed context window limitations that plague standard LLMs.
The architecture delivers compelling benchmark results:
26% higher response accuracy compared to OpenAI's memory
91% lower p95 latency compared to full-context methods
90% savings in token usage, making memory practical at scale
Mem0's pipeline consists of two phases: Extraction and Update. This ensures only the most relevant facts are stored and retrieved, minimizing both tokens and latency. A Pareto efficiency analysis identifies Mem0 as the optimal choice for balancing cost and accuracy in distributed multi-agent systems.
LoCoMo & LLM-as-Judge Results
On the LOCOMO benchmark designed for long-term conversational memory evaluation, Mem0 demonstrates strong performance:
Metric | Value |
|---|---|
Overall Accuracy | 66.9% |
Median Latency | 0.20s |
p95 Latency | |
Tokens per Conversation |
Mem0 delivers a 26% relative uplift in overall LLM-as-a-Judge score over OpenAI's memory feature, achieving 66.9% versus 52.9%. This underscores its superior factual accuracy and coherence.
The graph-enhanced variant, Mem0g, achieves approximately 2% higher overall scores than the base configuration by storing memories as directed, labeled graphs.
Why Does Cortex's Self-Improving Memory Layer Out-Scale Vector Stores?
Cortex provides persistent memory infrastructure for AI agents through a layered architecture combining ACID conversations, vector index, facts extraction, and graph database capabilities. The system delivers real-time sync via Convex reactive queries, enabling semantic memory with infinite context.
The platform supports rich user preference tracking and context preservation across all agent interactions. Unlike stateless vector databases, Cortex maintains isolated user/agent boundaries with optional collaboration, addressing enterprise multi-tenancy requirements.
Cortex's architecture offers several capabilities relevant to scale:
Semantic Memory: Store and retrieve using natural language
Real-Time Sync: No stale data across clients
Context Chains: Hierarchical context propagation for multi-agent systems
Graph Integration: Optional Neo4j/Memgraph for relationship-rich context
On LongMemEval-s, the industry benchmark for long-term conversational memory across 115k+ token contexts, Cortex achieved 90.23% overall accuracy, the highest reported score to date. The system showed particularly strong performance in temporal reasoning, knowledge updates, and user preference understanding.
How Does Cortex Preserve Chronology Across Thousands of Agents?
Cortex supports multi-agent coordination through two primary modes:
Hive Mode: Shared memory for MCP and personal AI applications
Collaboration Mode: Autonomous multi-agent systems with isolated spaces
The platform uses context chains for hierarchical context propagation, enabling agents to inherit relevant context from parent workflows while maintaining their own state.
LLM-extracted structured facts provide 60-90% storage savings, transforming conversations into structured knowledge. This approach enables 99% token reduction through fact extraction, meaning infinite context fits in finite windows.
Mem0 vs Cortex: Which Platform Wins on Cost, Latency & Governance?
Both platforms target production multi-agent deployments, but their architectures optimize for different trade-offs.
Mem0 significantly outperforms graph-based alternatives like Graphiti in efficiency, featuring faster loading times, lower resource consumption, and minimal network overhead. Accuracy differences between vector and graph approaches were not statistically significant in distributed multi-agent testing.
Cortex counters with its hybrid architecture. As the documentation states, the system achieves "99% token reduction through fact extraction means infinite context fits in finite windows." The platform maintains sub-second latency while scaling to millions of memories.
Operational Cost & Token Footprint
Platform | Token Usage | Latency Profile | Storage Approach |
|---|---|---|---|
Mem0 | 90% savings vs full-context | 0.20s median, 0.15s p95 | Vector + optional graph |
Cortex | 60-90% savings via fact extraction | Sub-second at scale | ACID + Vector + Facts + Graph |
Mem0 encodes complete dialogue turns in natural language representation, occupying only 7k tokens per conversation on average. The graph-enhanced variant roughly doubles the footprint to 14k tokens due to relationship storage.
Cortex's fact extraction layer provides 60-90% storage savings while maintaining the full audit trail through append-only ACID conversations.
Isolation, Compliance & Audit Trails
Both platforms address enterprise governance requirements, though with different approaches.
Mem0's Platform API separates memories for different users, agents, and apps through entity-scoped memory. The platform provides private memory spaces for multi-tenant deployments where different agents need separate contexts for the same user. Enterprise controls include SOC 2, audit logs, and workspace governance by default.
Cortex maintains strict isolation by default with optional collaboration. The platform includes GDPR cascade deletion with complete audit trails, one-click deletion across all layers with built-in compliance and governance.
Which Agent Frameworks Plug-In with Minimal Effort?
Integration complexity varies significantly between platforms.
CrewAI, a lightweight Python framework for orchestrating autonomous AI agents, offers documented integration with Mem0. This enables persistent memory across agent interactions and personalized task execution based on user history. The integration maintains user preferences and conversation history across sessions.
Cortex provides native edge runtime compatibility, working with Vercel AI SDK, OpenAI SDK, and LangChain. The platform is framework-agnostic and embedding-agnostic, supporting OpenAI, Cohere, and local models.
Key integration considerations:
Mem0 + CrewAI: Established integration for role-based agent architectures
Cortex: Framework-agnostic design with MCP integration for cross-tool memory
Both: Support for major embedding providers and LLM backends
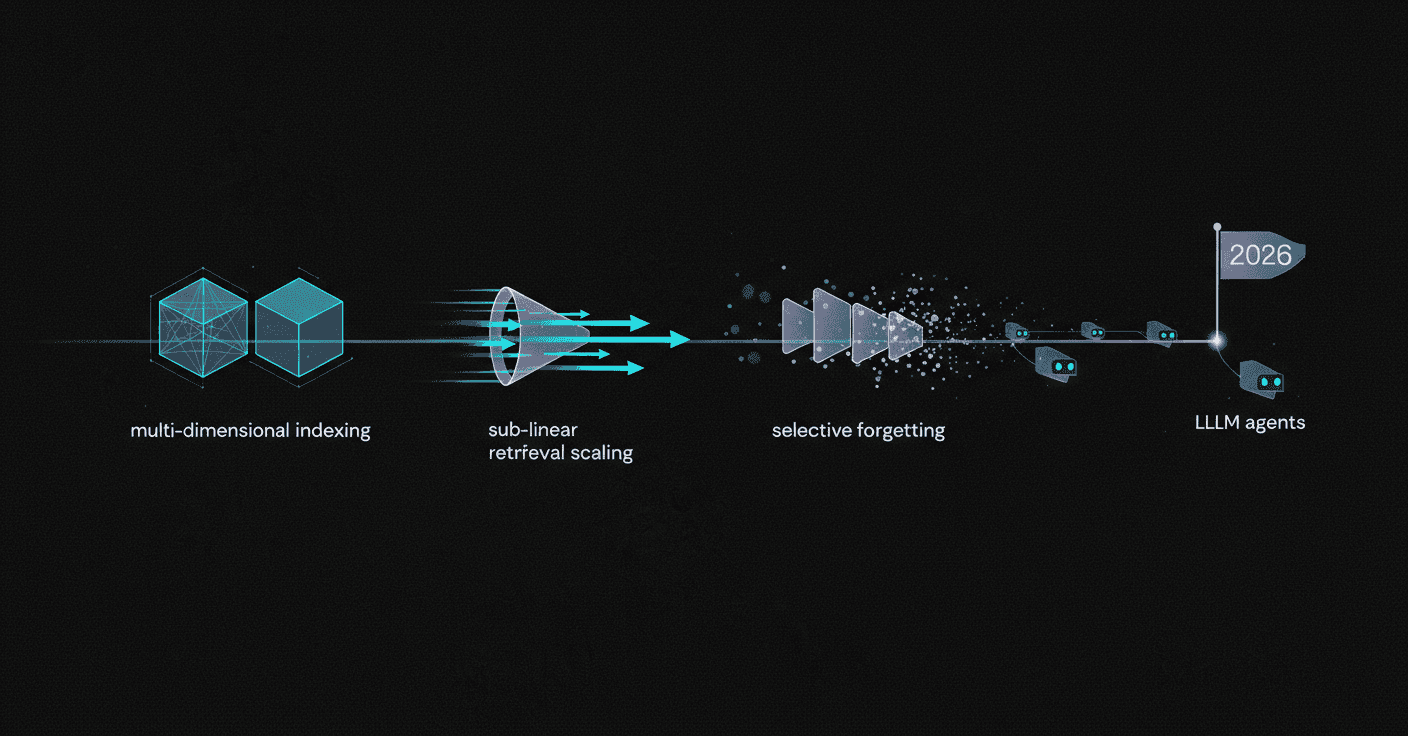
What Emerging Research Means for Your 2026 Roadmap
Several research directions will influence memory architecture decisions over the next year.
SwiftMem introduces query-aware indexing for agentic memory, achieving 47x faster retrieval compared to state-of-the-art baselines while maintaining competitive accuracy. The system uses specialized temporal and semantic indexing for sub-linear retrieval times.
MAGMA proposes multi-graph agentic memory architecture representing each memory item across orthogonal semantic, temporal, causal, and entity graphs. Experiments show MAGMA consistently outperforms existing systems in long-horizon reasoning tasks on LoCoMo and LongMemEval benchmarks.
MemoryAgentBench reveals that "current methods fall short of mastering all four competencies, underscoring the need for further research into comprehensive memory mechanisms for LLM agents." The four competencies evaluated are accurate retrieval, test-time learning, long-range understanding, and selective forgetting.
These research directions suggest that production memory systems will increasingly need:
Multi-dimensional indexing (temporal, semantic, causal)
Sub-linear retrieval scaling
Selective forgetting capabilities
Improved test-time learning
Choosing the Right Memory Layer for 2026 and Beyond
The choice between Mem0 and Cortex depends on your deployment context and scaling requirements.
Mem0 delivers proven cost efficiency. Pareto analysis identifies it as optimal for balancing cost and accuracy in distributed agent tests. The platform excels in single-tenant scenarios where token efficiency matters most, with documented integrations for frameworks like CrewAI.
Cortex provides a self-improving memory layer with temporal reasoning capabilities validated against LongMemEval-s benchmarks. The platform's Hive mode enables shared memory across agent fleets, while tenant isolation supports enterprise multi-agent deployments.
For teams building production-grade AI agents where accuracy, latency, personalization, and long-term learning matter more than raw embeddings, Cortex offers a memory-first platform that scales from personal AI assistants to enterprise multi-agent systems. The architecture replaces fragmented retrieval stacks with a unified, self-improving layer that handles ingestion, search, personalization, memory, and answer generation out of the box.
Frequently Asked Questions
What are the key differences between Mem0 and Cortex for multi-agent systems?
Mem0 focuses on cost efficiency and token usage, making it optimal for single-tenant scenarios. Cortex offers a self-improving memory layer with strong temporal reasoning, ideal for enterprise multi-agent deployments.
How does Cortex's memory architecture benefit multi-agent systems?
Cortex's architecture supports persistent memory, real-time sync, and context chains, enabling effective multi-agent coordination and long-term learning. It achieves high accuracy in temporal reasoning and knowledge updates.
What are the advantages of Mem0's memory-centric architecture?
Mem0 provides scalable memory solutions with high response accuracy and low latency. It optimizes token usage and balances cost and accuracy, making it suitable for distributed multi-agent systems.
How does Cortex ensure data privacy and compliance in multi-agent systems?
Cortex maintains strict isolation with optional collaboration, offering GDPR compliance, audit trails, and one-click deletion across all layers, ensuring data privacy and governance.
Which platform is more suitable for production-grade AI agents?
Cortex is more suitable for production-grade AI agents due to its self-improving memory layer, strong temporal reasoning, and ability to handle complex multi-agent deployments with high accuracy and personalization.