
How to Refresh or Update Stored LLM Memory
Refreshing LLM memory involves detecting stale information, implementing structured operations like ADD/UPDATE/DELETE, and using temporal-aware architectures. Modern solutions like Cortex provide self-improving memory that learns from usage patterns while maintaining version history through temporal knowledge graphs.
Key Facts
• Memory operations matter: Structured ADD, UPDATE, DELETE operations outperform naive append-only approaches for maintaining accurate agent context
• Temporal awareness is critical: Facts need timestamps and version history to handle queries like "Where did I live before 2023?" correctly
• Setup is streamlined: Getting started requires just three commands - install CLI, initialize project, and start development
• Multi-tenancy support: Latest v0.28.0 release includes complete multi-tenancy with tenantId propagation and Sessions API for user management
• Self-improvement capabilities: Memory systems learn user preferences for formats, content types, and query patterns over time
• Real-time sync: Built on Convex for instant updates across all clients without polling or stale data issues
Refreshing LLM memory management is essential for agents that need up-to-date facts and context across sessions. This guide shows engineers how to detect stale memories, choose refresh architectures, and use Cortex to automate updates.
Why Refreshing Memory Matters for Modern LLM Agents
Large Language Models have demonstrated impressive capabilities across a wide range of NLP tasks, but they remain fundamentally stateless, constrained by limited context windows that hinder long-horizon reasoning. When an agent forgets a user's preferences from last week or retrieves outdated project details, the downstream effects ripple through every response.
The LongMemEval benchmark, presented at ICLR 2025, evaluates five core long-term memory abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. With 500 meticulously curated questions embedded within freely scalable user-assistant chat histories, LongMemEval presents a significant challenge to existing systems, with commercial chat assistants and long-context LLMs showing a 30% accuracy drop on memorizing information across sustained interactions.
Research confirms that "episodic memory is the missing piece for long-term LLM agents." Episodic memory supports single-shot learning of instance-specific contexts, enabling rapid encoding of unique experiences. Without it, agents lose the contextual binding that tells them when, where, and why an event occurred.
Key takeaway: Persistent memory is no longer optional. Agents that fail to refresh their knowledge create user friction, degrade trust, and ultimately break in production.
What Makes Updating Long-Term LLM Memory So Hard?
Several technical hurdles stand between a working prototype and production-grade memory refresh:
Challenge | Why It Matters |
|---|---|
Temporal drift | Facts change over time; old answers become wrong answers |
Noisy context | Redundancy in natural language introduces noise, hindering precise retrieval |
Data readiness | 57% of organizations estimate their data is not AI-ready |
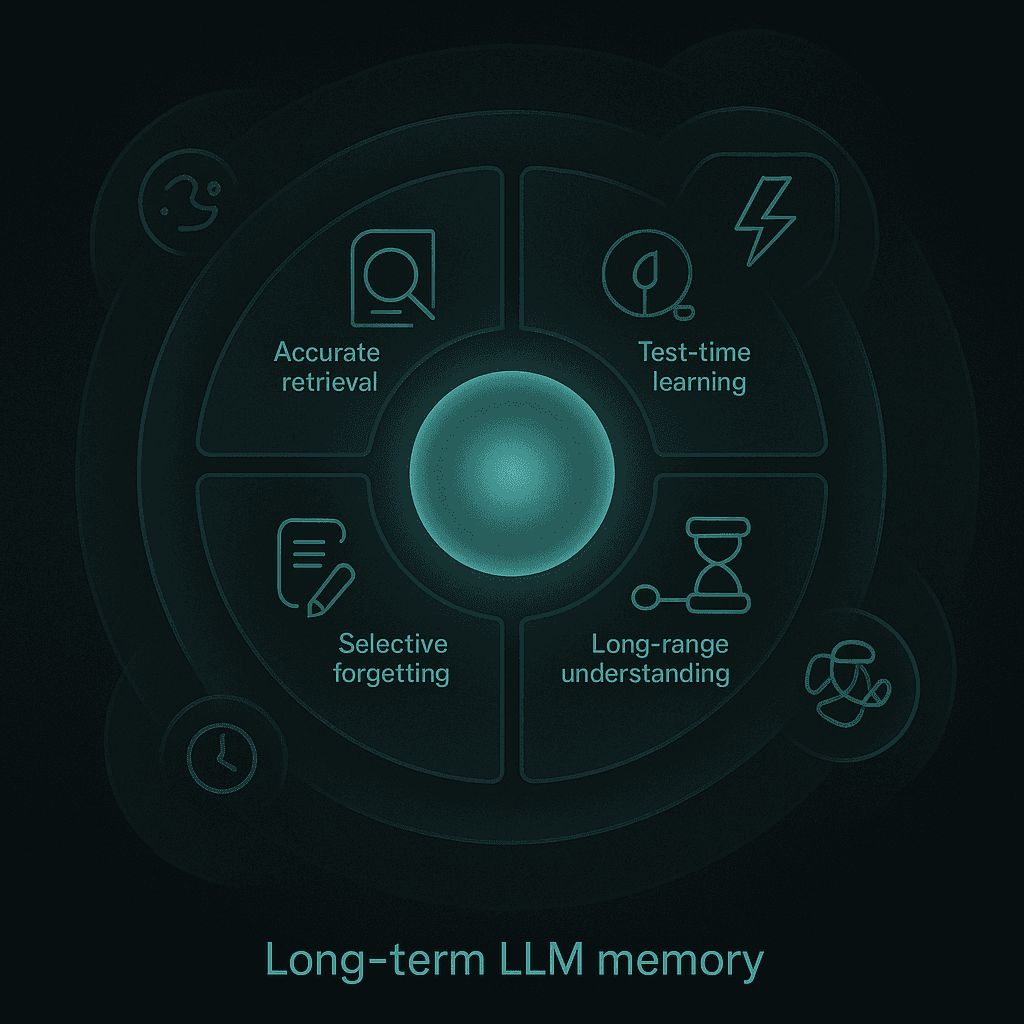
Competency gaps | Current methods fall short of mastering accurate retrieval, test-time learning, long-range understanding, and selective forgetting |
LLMs have showcased remarkable reasoning capabilities, yet they remain susceptible to errors in temporal reasoning tasks involving complex temporal logic. A user asking "Where did I live before 2023?" expects the agent to distinguish past from present, but most retrieval pipelines treat every fact as equally current.
Researchers identify four complementary competencies to evaluate memory agents:
Accurate Retrieval (AR): The ability to extract the correct snippet in response to a query.
Test-Time Learning (TTL): The capacity to incorporate new behaviors during deployment without additional training.
Long-Range Understanding (LRU): The ability to integrate information distributed across extended contexts (≥100k tokens).
Selective Forgetting (SF): The skill to revise, overwrite, or remove previously stored information when faced with contradictory evidence.
Empirical results reveal that current methods fall short of mastering all four competencies, underscoring the need for further research into comprehensive memory mechanisms.
Which Architectures Enable Continuous Memory Refresh?
Recent research has produced several patterns that move beyond naive append-only retrieval:
Memory-R1 Framework
Memory-R1 is the first RL framework for memory-augmented LLMs, consisting of a Memory Manager that performs structured operations (ADD, UPDATE, DELETE, NOOP) and an Answer Agent that filters and reasons over memories retrieved via RAG. Using the LLaMA-3.1-8B-Instruct backbone, Memory-R1-GRPO achieves relative improvements of 28% in F1, 34% in BLEU-1, and 30% in LLM-as-a-Judge across benchmarks including LoCoMo, MSC, and LongMemEval.
Agentic Memory (AgeMem)
AgeMem proposes a unified framework that integrates long-term and short-term memory directly into the agent's policy. It exposes memory operations as tool-based actions, enabling the LLM agent to autonomously decide what and when to store, retrieve, update, summarize, or discard information. AgeMem achieved the highest average performance on Qwen2.5-7B-Instruct (41.96%) with relative gains of 49.59% over no-memory baselines.
Hybrid Search Engines
Combining semantic vector search with full-text keyword search (BM25) and metadata-first filtering dramatically improves precision and recall. This hybrid approach scopes and filters results before retrieval, reducing hallucinations and ensuring the freshest context surfaces first.
How Does Cortex Enable Safe, Real-Time Memory Updates?
Cortex functions as a self-improving retrieval and memory layer that sits between an organization's data sources and its AI models, handling ingestion, search, personalization, memory, and answer generation out of the box.
Temporal Knowledge Graph
Cortex preserves chronology and knowledge evolution through a temporal, Git-style relationship graph. New information creates new versions rather than overwriting old facts, enabling temporal queries like "Where did I live before 2023?" to return correct answers. Full audit trails exist for how knowledge changed over time.
Native Integrations
Cortex connects directly to a wide range of data sources, including Gmail, Slack, Notion, Jira, internal tools and APIs, databases, PDFs, HTML, Markdown, and files. The Data Access API allows apps access to Slack data through a short-lived token for RAG queries, ensuring real-time context without storing customer information externally.
Self-Improving Personalization
"Cortex includes memory that improves over time. The system learns how individual users behave—what formats they prefer (e.g. tables, summaries), what content types they favor (e.g. spreadsheets, slides), and how they usually ask questions." — Cortex Documentation
This personalization makes every interaction feel tailored instead of generic, driving higher engagement and user satisfaction.
Step-by-Step Workflow: Refreshing Memory with the Cortex SDK
Getting started with Cortex takes three commands:
Install the CLI
brew install cortex-memory/tap/cliInitialize your project
cortex init my-projectStart development
cortex dev
Multi-Tenancy Support
Think of a tenant as a completely separate workspace in your Cortex application. A sub-tenant is like a department or team within an organization. The latest v0.28.0 release includes complete multi-tenancy support with tenantId propagation and a Sessions API for user session management.
Memory Configuration
Memory is where personalization lives. Unlike static knowledge, memory is dynamic and user-specific. Cortex memories update automatically through conversation, queries, and usage, giving your app the ability to learn, remember, and adapt.
Querying and Retrieval
Querying is how you extract meaningful answers from your knowledge and memory layers. Cortex gives you control over how retrieval works, using a combination of:
Top-K across documents, passages, or snippets
Alpha, recency bias, and contextual expansion
Verifiable citations with exact source snippets
Cortex vs. Other Memory Layers: Where Do Alternatives Fall Short?
The memory layer landscape includes several options. Here is how they compare on key dimensions:
System | Approach | LongMemEval Performance |
|---|---|---|
Zep | Temporal knowledge graph via Graphiti | Up to 18.5% accuracy improvement over baseline, 90% latency reduction |
Supermemory | Chunk-based ingestion with relational versioning | State-of-the-art on LongMemEval_s with 76.69% temporal reasoning |
Praxos | Advanced memory architecture | Reduces context window usage by more than 90% |
Cortex | Self-improving retrieval with temporal graph | 90.23% overall accuracy on LongMemEval-s |
Zep utilizes Graphiti, a temporally-aware knowledge graph engine that dynamically synthesizes both unstructured conversational data and structured business data while maintaining historical relationships. This makes it effective for enterprise-critical tasks.
LangGraph, an orchestration framework from the creators of LangChain, excels in managing complex workflows for LLM agents by implementing them as stateful graphs. It offers built-in state management and error recovery but relies on external tools like Zep for long-term memory persistence.
The key differentiator for production teams is whether the memory layer treats temporal reasoning as a first-class concern or an afterthought.
How Do You Measure Success? Benchmarks & Observability Tools
Validating refreshed memory requires both public benchmarks and in-house tracing:
Public Benchmarks
MemoryAgentBench is a new benchmark specifically designed for memory agents, providing comprehensive coverage of the four core memory competencies: accurate retrieval, test-time learning, long-range understanding, and selective forgetting.
The benchmark transforms existing long-context datasets into a multi-turn format, effectively simulating the incremental information processing characteristic of memory agents. Notably, the best performing GPT-5 model only achieves a 60% Correctness score on MEMTRACK, highlighting significant room for improvement.
Observability Tools
AI Observability in Snowflake Cortex allows teams to evaluate and trace generative AI applications using systematic evaluations and application traces for debugging. Key features include:
Evaluations for RAG and summarization tasks
Comparisons across application versions
Tracing every step from input prompts to tool use to LLM inference
Metrics such as accuracy, latency, usage, and cost enable rapid iteration on application configurations.
Key takeaway: Combine benchmark testing with production observability. Benchmarks validate architecture choices; traces reveal real-world failure modes.
Key Takeaways & Next Steps
Refreshing stored LLM memory is not a one-time fix but an ongoing system design challenge. The patterns that work share common traits:
Temporal awareness: Facts need timestamps and version history
Structured operations: ADD, UPDATE, DELETE beat naive append
Self-improvement: Memory should learn from usage, not just storage
Observability: You cannot improve what you cannot measure
Cortex doesn't just fetch documents. It learns, adapts, and gets smarter with time. For teams building production AI agents where accuracy, latency, personalization, and long-term learning matter more than raw embeddings or isolated vector similarity, exploring the Cortex documentation is a logical next step.
Frequently Asked Questions
Why is refreshing LLM memory important for AI agents?
Refreshing LLM memory is crucial because it ensures that AI agents have up-to-date facts and context, which is essential for accurate and reliable responses across sessions. Without refreshing, agents may retrieve outdated information, leading to user friction and degraded trust.
What challenges are associated with updating long-term LLM memory?
Updating long-term LLM memory involves overcoming challenges such as temporal drift, noisy context, data readiness, and competency gaps. These challenges can hinder precise retrieval and the ability to maintain accurate, long-term memory in AI systems.
How does Cortex facilitate real-time memory updates?
Cortex enables real-time memory updates by acting as a self-improving retrieval and memory layer. It uses a temporal knowledge graph to preserve chronology and knowledge evolution, ensuring accurate and up-to-date information retrieval. Cortex also integrates with various data sources for seamless context updates.
What are the key features of Cortex's memory management system?
Cortex's memory management system includes a temporal knowledge graph, native integrations with data sources, and self-improving personalization. These features allow Cortex to maintain accurate, personalized, and up-to-date memory, enhancing AI agent performance and user satisfaction.
How does Cortex compare to other memory layers?
Cortex stands out from other memory layers by offering self-improving retrieval with a temporal graph, achieving 90.23% overall accuracy on the LongMemEval-s benchmark. It emphasizes temporal reasoning and personalization, which are critical for production-grade AI applications.