
Why Do Voice Agents Forget Previous Conversations?
Voice agents forget previous conversations primarily due to fixed context windows that limit how much history can be processed, combined with fragile retrieval pipelines that fail to fetch relevant past information. Research shows commercial systems achieve only 30-70% accuracy on memory benchmarks, with 30% accuracy drops when memorizing information across sustained interactions.
TLDR
• Voice assistants struggle with multi-session memory due to technical constraints, not design choices - fixed context windows drop older information when limits are exceeded
• LongMemEval benchmark reveals 30-60% performance drops in long-context LLMs, with commercial systems achieving only 30-70% accuracy on memory tasks
• Audio-specific challenges compound the problem - spoken content requires 12-25 embeddings per second, burning through context windows faster than text
• Event-centric memory graphs and neuro-symbolic reasoning frameworks like TReMu show promise, improving temporal reasoning from 29.83 to 77.67 accuracy
• Enterprises are implementing dedicated memory layers today, with platforms like Cortex providing self-improving retrieval systems for production AI agents
Voice assistant memory is one of the most frustrating gaps in modern AI. You ask your smart speaker to remember your coffee order, and the next morning it asks you all over again. This forgetfulness is not a design choice. It is a technical limitation rooted in how these systems process, store, and retrieve information.
Understanding why voice agents lose track of past conversations matters for anyone building or deploying AI that needs to feel continuous and personal. The problem touches on fixed context windows, fragile retrieval pipelines, and the unique challenges of spoken audio. The good news: emerging architectures are starting to solve it.
Why do smart speakers keep asking the same question?
Voice assistants like Apple Siri and Amazon Alexa have become part of daily life, enabling natural speech-based interactions. Yet despite years of advancement, most current models excel only in single-turn interactions. Ask a follow-up question that references something from yesterday, and the assistant treats it as a brand-new conversation.
This gap is not just annoying. It undermines trust. When an assistant forgets your preferences, your context, or even what you just said, it stops feeling like a tool and starts feeling like a stranger.
Long-context reasoning remains a fundamental challenge for large language models, as excessively long inputs often lead to the forgetting of salient information. The result: your voice agent cannot recall what happened five minutes ago, let alone five days.
What technical limits erase past conversations?
The root causes of forgetfulness in voice agents fall into three main categories: context window constraints, retrieval fragility, and audio-specific overhead.
Fixed context windows & token budgets
Every large language model has a context window, the maximum amount of text it can consider at once. When your conversation history exceeds this limit, older information simply gets dropped.
As one research paper puts it, "LLM-based conversational agents still struggle to maintain coherent, personalized interaction over many sessions: fixed context windows limit how much history can be kept in view, and most external memory approaches trade off between coarse retrieval over large chunks and fine-grained but fragmented views of the dialogue."
Long-context reasoning remains a fundamental challenge for LLMs, with excessively long inputs often leading to the forgetting of salient information.
Fragile retrieval pipelines
Even when systems try to retrieve relevant past context, the pipelines are brittle. Research on voice interaction models identifies a major challenge: "Sensitivity to retrieval errors, models are highly susceptible to retrieval mistakes, leading to unchanged or even degraded performance."
If the retriever fetches the wrong snippet, or fails to fetch anything at all, the model answers as if the past never happened.
What do the numbers say: Benchmarks expose the memory gap
Benchmarks designed to stress-test memory reveal just how severe the problem is.
LongMemEval: 30 % accuracy drop
LongMemEval is a comprehensive benchmark designed to evaluate five core long-term memory abilities of chat assistants: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention.
The results are stark: commercial chat assistants and long-context LLMs show a 30% accuracy drop on memorizing information across sustained interactions. Preliminary evaluations highlight the difficulty, as long-context LLMs show a 30% to 60% performance drop on LongMemEval-S, and manual evaluations reveal that state-of-the-art commercial systems only achieved 30% to 70% accuracy in settings much simpler than the full benchmark.
Vox-Infinity & Audio-MultiChallenge for speech
Audio benchmarks reveal even steeper challenges.
Vox-Infinity is the first benchmark specifically designed to evaluate long-context understanding in spoken language models. It extends audio history along two dimensions: turns and duration, covering scenarios like ultra multi-turn dialogues and personal monologues.
Audio MultiChallenge evaluates end-to-end spoken dialogue systems under natural multi-turn interaction patterns. The results are sobering: even frontier models struggle, with the highest-performing model, Gemini 3 Pro Preview (Thinking), achieving only a 54.65% pass rate.
Error analysis shows that models fail most often on new evaluation axes and that self-coherence degrades with longer audio context.
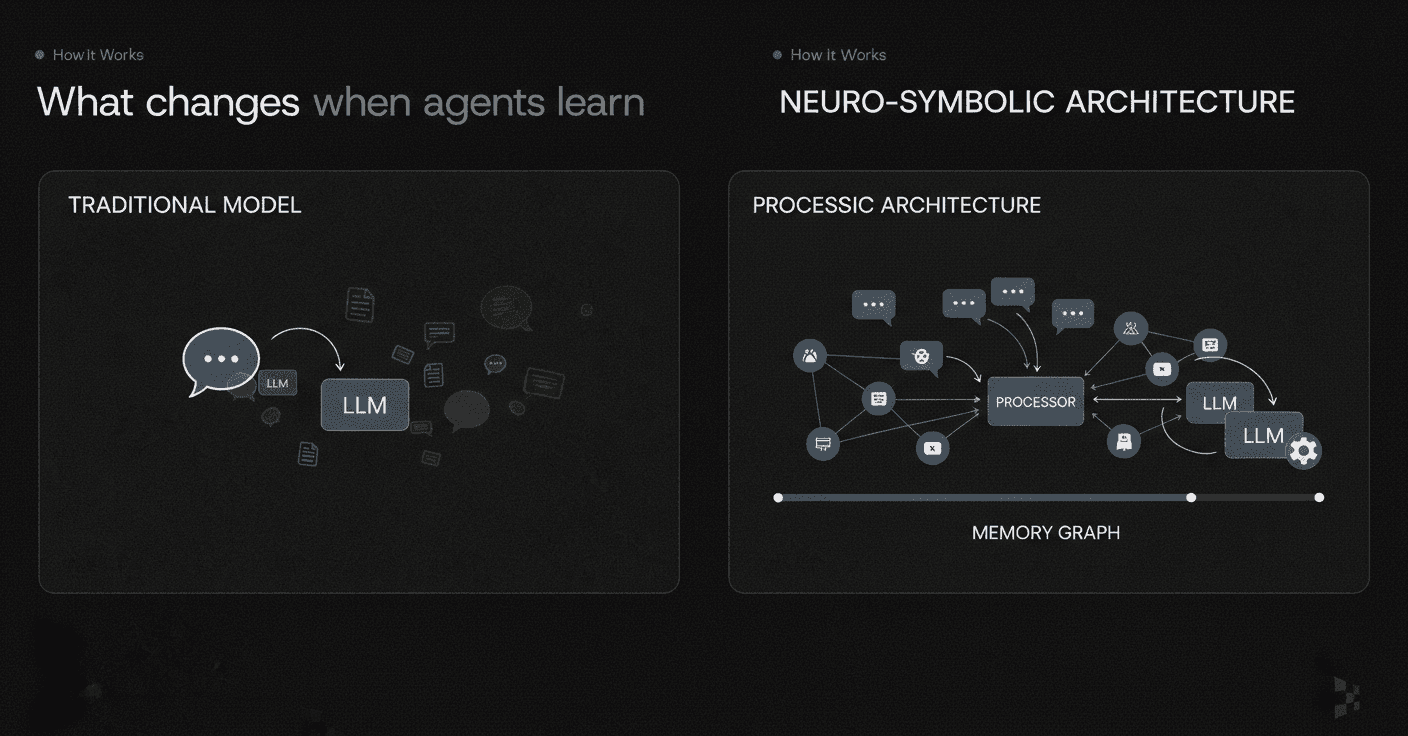
Which architectures actually help agents remember?
Researchers and engineers are exploring several promising memory designs. The most effective share a common trait: they treat memory as a first-class architectural component, not an afterthought.
Event-centric memory graphs
One approach represents conversational history as short, event-like propositions that bundle together participants, temporal cues, and minimal local context, rather than as independent relation triples or opaque summaries. Researchers propose an event-centric alternative that preserves information in a more accessible form.
Concretely, an LLM decomposes each session into enriched elementary discourse units (EDUs), self-contained statements with normalized entities and source turn attributions, and organizes sessions, EDUs, and their arguments in a heterogeneous graph that supports associative recall.
Another system, MemoriesDB, combines the properties of a time-series datastore, a vector database, and a graph system within a single append-only schema, providing a viable substrate for maintaining coherence across long temporal spans.
Neuro-symbolic temporal reasoning (TReMu, TempAgent)
Temporal reasoning in multi-session dialogues presents a significant challenge that has been under-studied in previous benchmarks.
TReMu is a new framework aimed at enhancing the temporal reasoning capabilities of LLM-agents in this context. The proposed framework significantly improves temporal reasoning performance, raising from 29.83 to 77.67 with the new approach.
TempAgent, another framework, achieves a 41.3% improvement over baseline and a 32.2% gain compared to the Abstract Reasoning Induction (ARI) method. It attains an accuracy of 70.2% on the Hits@1 metric, underscoring its advantage in addressing time-aware tasks.
Key takeaway: Event-centric graphs and neuro-symbolic reasoning can dramatically improve an agent's ability to remember and reason over time.
Why is spoken modality tougher than chat for memory?
Voice agents face unique challenges compared to text-based assistants.
Spoken content typically requires 12 to 25 embeddings per second to encode, resulting in much longer input sequences than text for conveying equivalent semantic information. This means audio burns through context windows far faster than text.
Research findings show that speech-based models have more difficulty than text-based ones, especially when recalling information conveyed in speech. Even with retrieval-augmented generation, models still struggle with questions about past utterances.
Error analysis shows that models fail most often on new axes and that self-coherence degrades with longer audio context. The modality gap is real, and it compounds the memory problem.
How are enterprises adding memory layers today?
Enterprises are not waiting for perfect solutions. They are building memory layers into their AI assistants now.
Telnyx, for example, developed AIDA, an internal AI Digital Assistant integrated into Slack. A key lesson from their deployment: "Meaningful internal adoption requires persistent context, safe system access, and clear boundaries around responsibility." AIDA initially faced challenges with statelessness, where context would disappear after conversations. To solve this, Telnyx integrated Mem0 as its memory layer to retain context across interactions.
Gartner predicts that 33% of enterprise software applications will include agentic AI by 2028, while 15% of day-to-day work decisions will be made autonomously through AI agents.
SlackAgents, another framework, enables seamless agent-to-agent and agent-to-human collaboration, leveraging Slack's messaging infrastructure to orchestrate complex workflows and automate real-world tasks.
From forgetful to forever: building vocal agents that truly remember
The gap between what voice agents promise and what they deliver comes down to memory. Fixed context windows, fragile retrieval, and audio overhead all contribute to the problem. But the research is clear: event-centric architectures, neuro-symbolic reasoning, and dedicated memory layers can close the gap.
Event sourcing is the right foundation, offering immutable events with projections that give you auditability, flexibility, and clean separation of concerns.
For teams building production AI agents, investing in a robust memory layer is no longer optional. Platforms like Cortex are designed specifically to address these challenges, providing a self-improving retrieval and memory platform that preserves context, enables temporal reasoning, and adapts as your organization evolves.
The future of voice agents is not about bigger context windows. It is about smarter memory.
Frequently Asked Questions
Why do voice agents forget previous conversations?
Voice agents often forget past conversations due to technical limitations like fixed context windows, fragile retrieval pipelines, and the unique challenges of processing spoken audio. These factors prevent them from maintaining coherent, personalized interactions over multiple sessions.
What are context window constraints in voice agents?
Context window constraints refer to the limited amount of text or audio data a language model can process at once. When conversation history exceeds this limit, older information is dropped, leading to forgetfulness in voice agents.
How do fragile retrieval pipelines affect voice agent memory?
Fragile retrieval pipelines can lead to errors in fetching relevant past context. If the retrieval system fails to fetch the correct information or fetches nothing, the voice agent may respond as if the past conversation never occurred.
What solutions are emerging to improve voice agent memory?
Emerging solutions include event-centric memory graphs and neuro-symbolic temporal reasoning frameworks. These approaches treat memory as a core architectural component, enhancing the ability of voice agents to remember and reason over time.
How does Cortex help in improving AI memory?
Cortex provides a self-improving retrieval and memory platform that preserves context, enables temporal reasoning, and adapts to organizational changes. It addresses the challenges of fixed context windows and fragile retrieval, making AI agents more reliable and personalized.