
How do AI copilots store long-term memory?
AI copilots store long-term memory through vector databases, graph databases, or hybrid architectures that persist user interactions and preferences beyond single sessions. Modern systems like Microsoft 365 Copilot retain conversations for 18 months while research frameworks demonstrate 30x token reduction with improved accuracy through advanced compression techniques.
Key Facts
• Three core architectures: Vector databases excel at semantic similarity, graph databases handle relationship queries, and hybrid approaches combine both strengths for semantic understanding and relationship reasoning
• Production implementations vary: ChatGPT uses persistent embeddings across sessions, GitHub Copilot employs the Model Context Protocol for external data sources, and Microsoft 365 Copilot integrates with Microsoft Graph for organizational context
• Efficiency breakthroughs: SimpleMem achieves 26.4% better F1 scores while reducing tokens 30x, while R3Mem introduces reversible compression for reconstructing raw data from compressed memories
• Privacy controls required: Systems must implement user-controlled retention policies, personalization toggles, and comply with standards like ISO/IEC 42001 for AI management
• Performance benchmarks: Cortex AI achieved 90.23% overall accuracy on LongMemEval-s, demonstrating strong performance in temporal reasoning, knowledge updates, and user preference understanding.
• Memory prevents forgetting: Large context windows only delay information loss, but purpose-built memory layers prevent it entirely by maintaining persistent context across sessions
Every time you restart a chat and watch your AI assistant forget your name, your project context, and the conversation you had yesterday, you are experiencing the core limitation of stateless AI. Long-term memory transforms these forgetful tools into compounding knowledge partners that learn your preferences, recall past interactions, and deliver increasingly relevant assistance over time.
Why does long-term memory matter for AI copilots?
AI chatbots have evolved dramatically from their origins as stateless systems. Early assistants treated every conversation as a blank slate, forcing users to repeat context endlessly. Today's context-aware copilots can recall past interactions and preferences, fundamentally changing how humans collaborate with AI.
This shift matters because memory management addresses both short-term and long-term information storage outside the LLM's context window, allowing agents to retain context-specific knowledge and recall past experiences. Without persistent memory, every session starts from zero.
Two memory concepts are central to understanding how copilots remember:
Episodic memory refers to a system that "encodes, stores, and allows access to memories with unique phenomenological attributes," according to cognitive neuroscience research. In AI terms, this means remembering specific events, conversations, and user interactions.
Personalization builds on episodic memory by adapting responses based on accumulated user preferences, making each interaction more relevant than the last.
The distinction between knowing general facts (semantic memory) and remembering specific experiences (episodic memory) proves essential for AI agents that must balance broad knowledge with user-specific context.
Key takeaway: Long-term memory enables copilots to move from transactional one-off interactions to relationship-building assistants that compound value with each use.
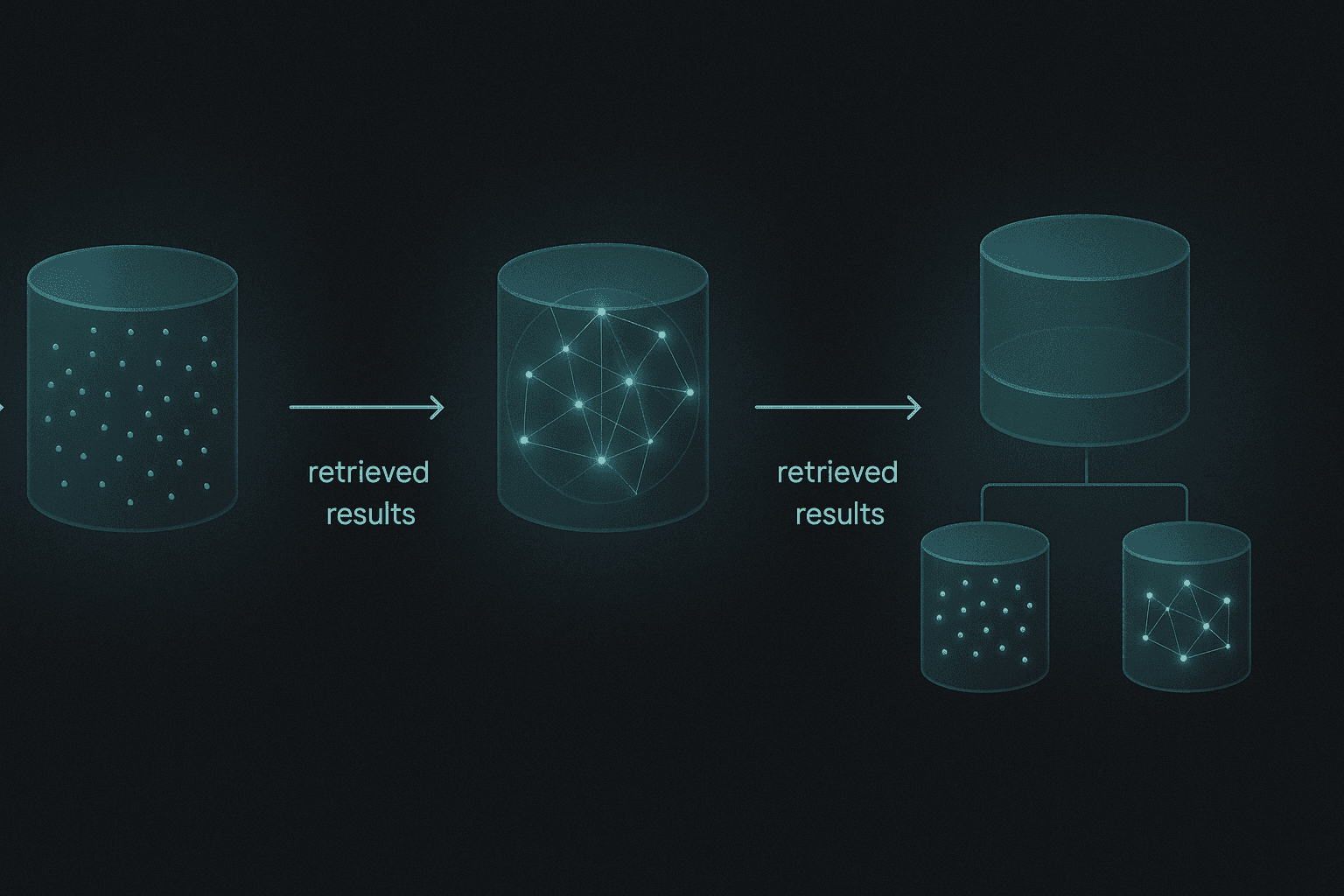
Core memory architectures: vector, graph and hybrid stores
AI agents require memory systems to maintain context, retrieve relevant information, and make informed decisions. Three primary architectural approaches have emerged to solve this challenge.
Vector databases
Vector databases store information as high-dimensional embeddings that capture semantic meaning. When a user asks a question, the system converts that query into an embedding and searches for the most similar stored memories.
These databases excel at semantic similarity matching but struggle with complex relationship queries. Embedding quality and model selection directly affect retrieval accuracy, making careful tuning essential.
As generative AI advances, vector databases have become critical infrastructure. Unlike traditional databases, they provide optimized support for multidimensional data and advanced similarity operations that enhance retrieval processes.
Graph databases
Graph databases take a different approach, storing information as nodes and edges that explicitly represent entities and their relationships. This structure makes them ideal for structured knowledge representation and complex relationship reasoning.
When you need to answer questions like "What projects has this user worked on with their colleague?" graph databases can traverse relationships efficiently where vector search would struggle.
Hybrid approaches
Hybrid architectures combine the strengths of both systems. They enable queries requiring semantic understanding and relationship reasoning, mitigating the individual limitations of pure vector or graph implementations.
Architecture | Strengths | Weaknesses |
|---|---|---|
Vector DB | Semantic similarity, flexible queries | Poor at relationship reasoning |
Graph DB | Relationship traversal, structured knowledge | Requires explicit schema |
Hybrid | Combines semantic and relational | Higher implementation complexity |
How do Microsoft 365, GitHub Copilot & ChatGPT keep context over time?
Production copilots implement memory through different strategies optimized for their use cases.
Microsoft 365 Copilot
Microsoft's approach grounds responses in organizational data through Microsoft Graph integration. When users interact with Copilot in apps like Word, PowerPoint, or Excel, the system stores the user's prompt and response, including citations to grounding information.
Conversations are retained by default for 18 months, according to Microsoft's Privacy FAQ. Users can enable personalization, which allows Copilot to remember key details from conversations for more tailored future responses.
GitHub Copilot
GitHub Copilot extends context through the Model Context Protocol (MCP), an open standard that defines how applications share context with LLMs. This protocol enables Copilot to connect to external data sources and tools without switching contexts.
Rather than storing long-term user memories directly, GitHub Copilot uses repository-level custom instructions and organization-wide configurations to maintain persistent context about coding preferences and project requirements.
ChatGPT and competing approaches
GPT-5's persistent embeddings enable users to carry conversations and documents across sessions without repeating context. Claude emphasizes reflection-driven memory for session consistency, while Gemini integrates retrieval-augmented long-term memory at scale.
Each approach optimizes for different priorities: GPT-5 leads in personalization, Claude maximizes session consistency, and Gemini dominates retrieval-driven workflows.
Beyond vectors: what do R3Mem, SimpleMem & Episodex teach us?
Recent research pushes memory capabilities further than production systems currently offer.
R3Mem: Reversible compression
R3Mem introduces a novel approach using virtual memory tokens and hierarchical compression. The system encodes long histories by refining information from document to entity level. Critically, R3Mem employs a reversible architecture that reconstructs raw data by invoking the model backward with compressed information.
"Experiments demonstrate that our memory design achieves state-of-the-art performance in long-context language modeling and retrieval-augmented generation tasks," according to the R3Mem research paper.
SimpleMem: Efficiency through compression
SimpleMem tackles the efficiency problem head-on. The framework outperforms Mem0 by 26.4% in F1 score while reducing token consumption by 30 times compared to full-context models.
The system achieves this through three stages:
Semantic Structured Compression filters information based on semantic utility
Recursive Memory Consolidation reorganizes stored memory incrementally
Adaptive Query-Aware Retrieval adjusts scope based on query complexity
Episodex: Cognitive architecture
Episodex segments reasoning into semantically coherent episodes and abstracts conceptual knowledge for reuse. Evaluated on out-of-distribution tasks, the architecture achieved an 87.5% success rate using GPT-4o.
The research demonstrates that memory-driven retrieval reduces average actions per task by over 30%, while conceptual memory clustering increased performance from 50% to 82%.
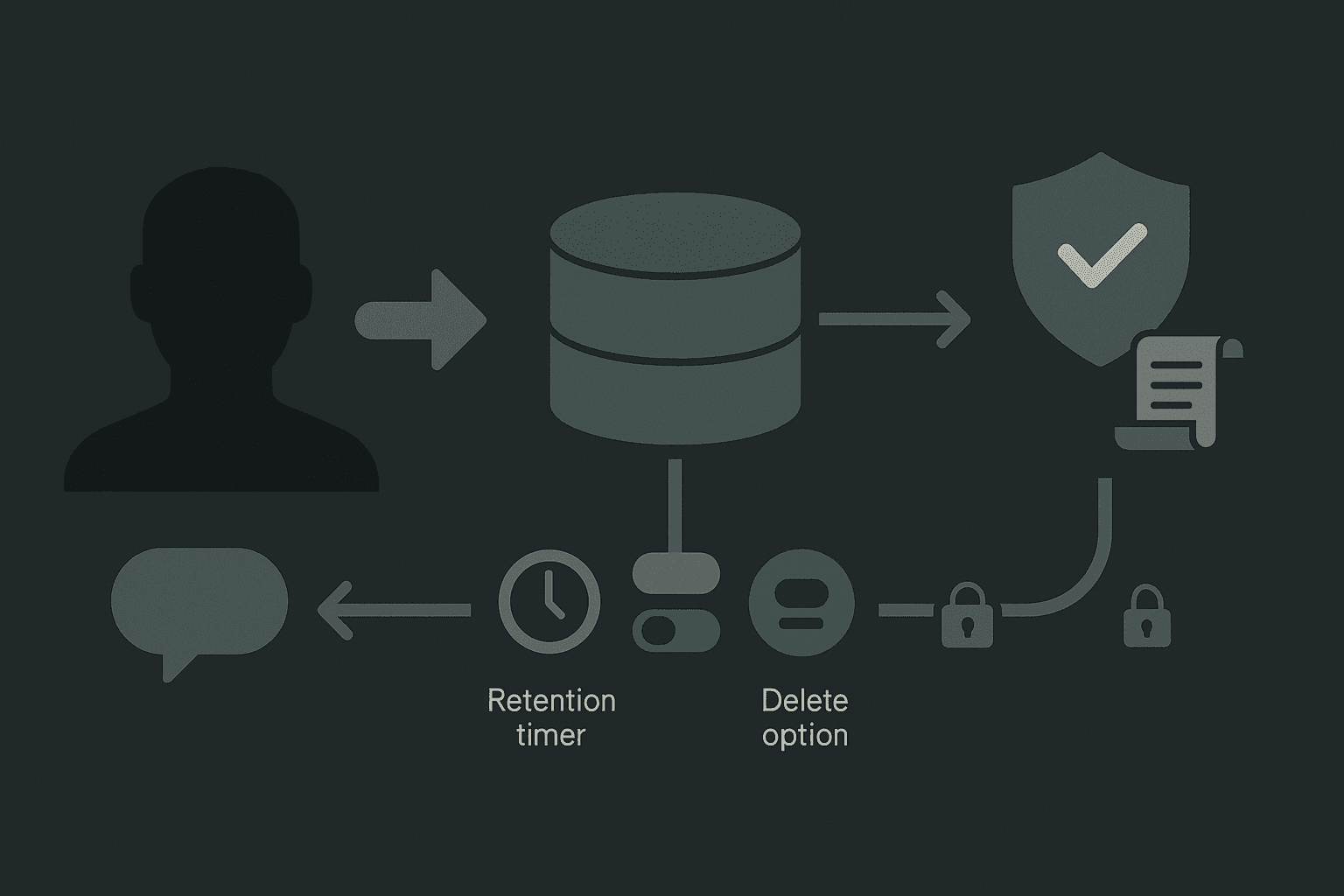
What privacy and compliance rules govern AI-copilot memory?
Storing user interactions creates significant privacy and compliance obligations that organizations must navigate carefully.
Data retention limits
Microsoft stores conversation data for 18 months by default. For abuse monitoring purposes, prompt and output data may be stored for up to 30 days, but this data is only reviewed if automated systems flag it.
Users retain control over personalization features and can disable memory at any time, stopping the copilot from using past conversation data for future personalization.
ISO/IEC 42001 requirements
The ISO/IEC 42001 standard for AI management systems establishes requirements for governing AI systems with continuous learning capabilities. Organizations must:
Perform AI system impact assessments at planned intervals
Establish risk assessment processes aligned with AI policy
Ensure systems are used according to intended purposes and documentation
Provide resources for continual improvement of AI management systems
Microsoft 365 Copilot holds certifications including GDPR, ISO 27001, HIPAA, and ISO 42001 compliance.
User controls
Production copilots implement granular user controls:
Users can view and delete past conversations
Personalization can be toggled on or off
Organizational admins can configure retention policies
Data is not used to train foundation models
How to choose the right memory layer for your copilot
Selecting the appropriate memory architecture depends on your specific requirements and constraints.
Selection criteria
Factor | Considerations |
|---|---|
Query complexity | Single-hop vs. multi-hop reasoning needs |
Latency requirements | Real-time chat vs. batch processing |
Token budget | Cost constraints for retrieval and generation |
Relationship density | How interconnected your data is |
Personalization depth | Session-level vs. long-term user modeling |
Benchmark results to consider
Preliminary benchmarks provide concrete guidance for evaluating memory layers. Cortex AI achieved the highest overall score on LongMemEval-s, an industry benchmark for long-term, multi-session conversational memory. Significant gains were observed in temporal reasoning, knowledge updates, and user-preference understanding, which are often considered the most challenging and useful aspects in real-world scenarios. Cortex AI set a new benchmark with 90.23% overall accuracy, outperforming previous bests by +5 points. Notable improvements include perfect scores in single-session-user and single-session-assistant categories, approximately 10% gain in temporal reasoning and preference understanding, and about 5% in knowledge updates. LongMemEval-s serves as a rigorous test for long-context retrieval, moving beyond simple lookups.
Category | Cortex AI* | Supermemory* | Zep** | Full-context** | Memo | Letta |
|---|---|---|---|---|---|---|
Single-session-user | 100% | 98.57% | 92.9% | 81.4% | - | - |
Single-session-assistant | 100% | 98.21% | 80.4% | 94.6% | - | - |
Single-session-preference | 80.00% | 70.00% | 56.7% | 20.0% | - | - |
Knowledge-up-to-date | 94.87% | 89.74% | 83.3% | 78.2% | - | - |
Temporal-reasoning | 90.97% | 81.95% | 62.4% | 45.1% | - | - |
Multi-session | 76.69% | 76.69% | 57.9% | 44.3% | - | - |
Overall | 90.23% | 85.2% | 71.2% | 60.2% | - | - |
Cortex AI* and Supermemory* evaluated using Gemini 3.0 Pro. Zep** and Full-context** baselines evaluated using GPT-4o. No public results available for Memo & Letta on LongMemEval.
Agent memory architecture choice significantly impacts capabilities and performance. Large context windows delay forgetting, but a purpose-built memory layer prevents it.
Memory-first platforms
For teams building production AI agents, platforms like Cortex provide memory as a first-class primitive rather than an afterthought. A memory-first approach means persistent memory across conversations, user-specific personalization, and contextual adaptation that improves with use, all integrated directly into the retrieval layer rather than bolted on as a separate system.
Memory layers that persist across multiple sessions, agents, and models build sophisticated user profiles that enhance personalization and adaptability over time.
Key takeaways
AI copilot memory has evolved from simple context windows to sophisticated architectures combining vectors, graphs, and compression techniques. The key principles for implementation:
Architecture matters: Choose between vector, graph, or hybrid based on your query complexity and relationship density requirements.
Efficiency is achievable: Modern frameworks like SimpleMem and R3Mem demonstrate that you can reduce token consumption by 30x while improving accuracy.
Privacy requires planning: Implement clear retention policies, user controls, and compliance frameworks like ISO/IEC 42001 from the start.
Memory prevents forgetting: Large context windows delay forgetting; purpose-built memory layers prevent it entirely.
For teams shipping production AI experiences, Cortex offers a memory-first context and retrieval platform that handles ingestion, search, personalization, and memory as an integrated system rather than a fragmented stack. The result is AI that gets more accurate and useful over time without infrastructure complexity.
Frequently Asked Questions
What is the importance of long-term memory in AI copilots?
Long-term memory allows AI copilots to remember past interactions and user preferences, transforming them from transactional tools into relationship-building assistants that provide increasingly relevant assistance over time.
How do vector and graph databases differ in AI memory systems?
Vector databases store information as high-dimensional embeddings for semantic similarity, while graph databases use nodes and edges to represent entities and relationships, ideal for structured knowledge and complex queries. Hybrid systems combine both for enhanced capabilities.
How does Microsoft 365 Copilot manage user data and privacy?
Microsoft 365 Copilot integrates with Microsoft Graph to store user prompts and responses, retaining conversations for 18 months by default. Users can control personalization features and data retention, ensuring compliance with privacy standards like GDPR and ISO 42001.
What are some advanced memory architectures for AI agents?
Advanced architectures like R3Mem and SimpleMem use techniques like reversible compression and semantic structured compression to enhance memory efficiency and accuracy, reducing token consumption while improving performance in long-context tasks.
How does Cortex enhance AI copilot memory?
Cortex provides a memory-first context and retrieval platform, integrating persistent memory, user-specific personalization, and contextual adaptation directly into the retrieval layer, improving AI accuracy and usefulness over time without infrastructure complexity.
Sources
https://www.bsigroup.com/en-GB/products-services/certification/AI-Management-System/
https://ojs.aaai.org/index.php/AAAI-SS/article/download/27688/27461/31739
https://www.sciencedirect.com/science/article/abs/pii/S1364661319302323
https://www.forrester.com/report/vector-databases-explode-on-the-scene/RES181242
https://learn.microsoft.com/en-us/copilot/microsoft-365/microsoft-365-copilot-privacy
https://openreview.net/pdf/5d5d2f33adbaffe79864498018cd6d09d588083e.pdf
https://learn.microsoft.com/en-us/microsoft-copilot-service/copilot-data-movement-geos