How to Extend LLM Memory for SaaS Tools
Extending LLM memory for SaaS tools requires implementing external storage systems that retrieve relevant context on-demand rather than cramming everything into prompts. The most effective approach combines extraction/update loops with vector databases, which cuts token consumption by 90 percent while maintaining factual accuracy across extended conversations beyond the model's native context window. Cortex AI, for example, has demonstrated 90.23% overall accuracy on the LongMemEval-s benchmark, showcasing its ability to handle long-term, multi-session conversational memory.
Key Facts
• Memory architecture patterns: Extraction/update loops process conversations in two phases, comparing new facts against existing vector stores to minimize redundancy and maintain high accuracy, as demonstrated by Cortex AI's 90.23% overall accuracy on the LongMemEval-s benchmark.
• Storage backend options: Vector databases deliver sub-millisecond retrieval for semantic similarity, while graph-augmented variants add explicit relationship modeling, contributing to strong temporal reasoning performance.
• Cost reduction impact: Lean memory layers reduce token usage by 90% compared to prompt stuffing, making extended conversations financially viable at scale.
• Performance benchmarks: Cortex AI achieved a 90.23% overall accuracy on the LongMemEval-s benchmark, with significant gains in temporal reasoning, knowledge updates, and user-preference understanding.
• Production requirements: Memory systems need SOC 2 compliance, encryption at rest and in transit, and auditability for enterprise deployments.
SaaS teams building AI agents eventually hit a wall: the transformer forgets. Once a conversation exceeds the model's context window, facts vanish and users start repeating themselves. If your product depends on continuity -- customer support bots, sales copilots, internal knowledge assistants -- you need to extend LLM memory beyond what the model ships with.
This guide walks through what extended memory actually means, why SaaS products stall without it, which architectural patterns work in production, how to choose a backend, and how to layer personalization and governance on top.
What Does It Mean to Extend LLM Memory?
Large language models are constrained by limited context windows, which limits their usefulness in tasks like extended conversations and document analysis. Once the conversation exceeds that window, the model forgets.
Extended memory solves this by giving the LLM access to facts it cannot hold natively. Instead of cramming everything into the prompt (prompt stuffing), you store salient information externally and retrieve only what matters for the current turn.
A practical definition comes from the Memoria framework: agentic memory is "the capacity of an LLM agent implementation to recall, adapt to, and reason over past interactions to simulate the behaviour of a coherent, goal-directed agent" (arXiv).
For SaaS agents, that translates to:
Remembering a customer's preferences across sessions
Surfacing prior tickets when the same user returns
Adapting tone and format to individual workflows
Cortex, for example, treats memory as a first-class primitive. It is persistent across conversations, user-specific, and tenant-aware, so agents remember interactions.
Why SaaS LLMs Hit the Context Wall
Three forces conspire against stateless LLMs in production SaaS environments.
Token limits blow up costs. Passing the entire conversation history into every call inflates token usage. A lean memory layer can cut token consumption by 90 percent while raising accuracy.
Customer trust erodes. Users expect the assistant to recall what they said yesterday. When it doesn't, they lose confidence and churn. Solutions like Cortex AI, with its proven 90.23% overall accuracy on LongMemEval-s, address this by ensuring consistent and reliable memory.
The gen AI paradox persists. Nearly eight in ten companies report using gen AI, yet just as many report no significant bottom-line impact. Memory is one lever that shifts gen AI from a reactive tool to a proactive collaborator.
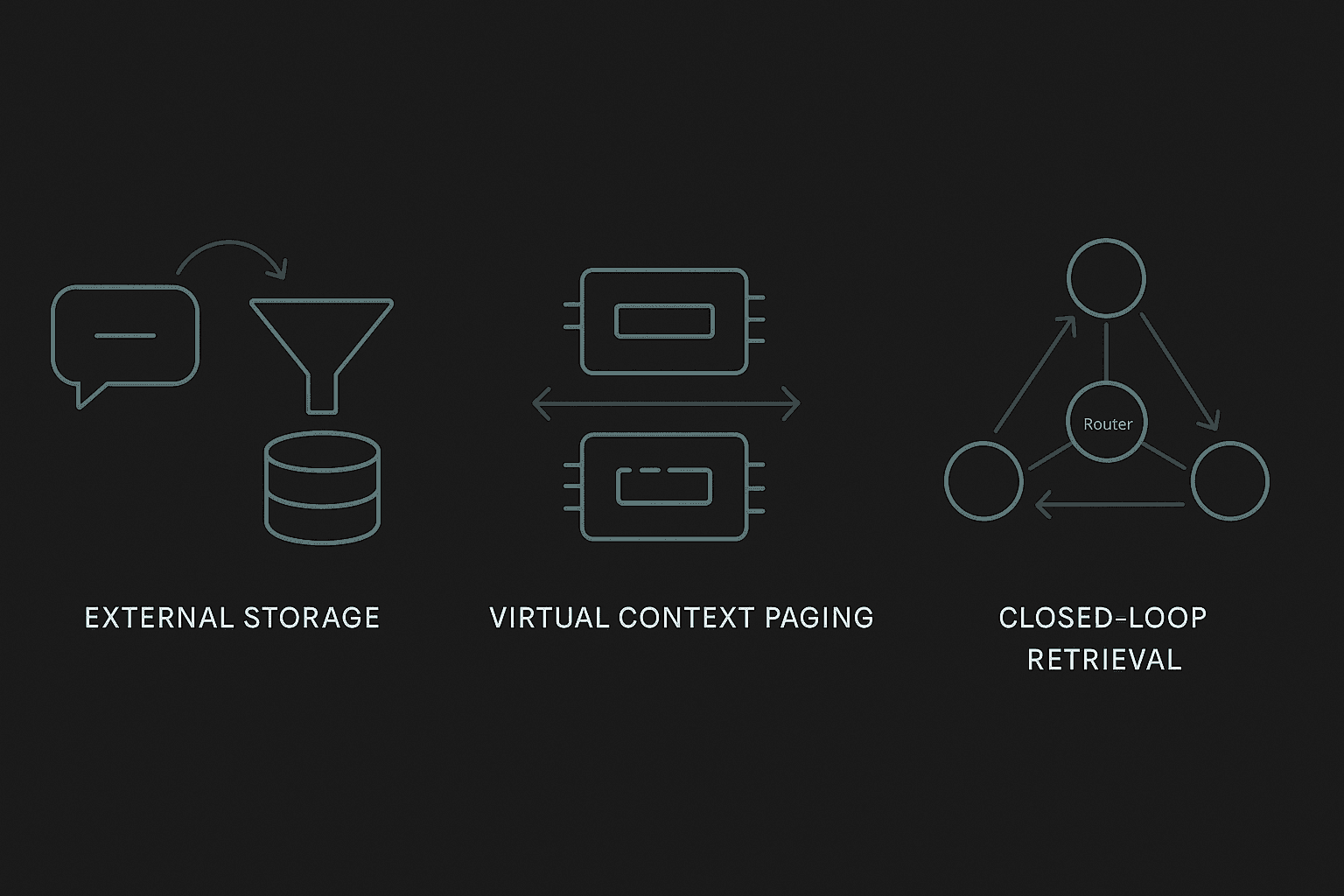
Architectural Patterns to Extend Memory
Production teams use three main patterns -- often in combination -- to give agents durable context.
Pattern | How It Works | Best For |
|---|---|---|
Extraction / Update Loops | Two-phase pipeline: extract candidate memories, then add, update, or delete against existing store | Long-horizon conversations with evolving facts |
Virtual Context Paging | Page information between RAM-like main context and disk-like archival storage | Document analysis, multi-hop reasoning |
Closed-Loop Retrieval | Router dynamically switches between Retrieve, Reflect, and Answer nodes while tracking evidence gaps | Complex Q&A requiring iterative lookup |
An OS-inspired architecture delineates between main context and external context, analogous to RAM and disk. The system pages data in and out so the model can handle larger effective context lengths without ballooning prompt size.
Another approach transforms retrieval into a closed-loop process: a router node selects among retrieve, reflect, and answer actions while a global evidence-gap tracker maintains what is known and what is still missing.
Extraction / Update Loops
A common pipeline illustrates the two-phase approach:
Extraction Phase -- Ingest the latest exchange, a rolling summary, and recent messages. An LLM extracts candidate memories.
Update Phase -- Compare each new fact to similar entries in the vector store. The model chooses ADD, UPDATE, DELETE, or NOOP.
This loop raised factual accuracy by 26 percent while cutting token use by 90 percent -- making memory practical and affordable at scale.
Key takeaway: A lean extraction/update loop keeps storage minimal, latency low, and costs in check while preserving the facts that matter.
Cortex AI's LongMemEval-s Performance
Cortex AI has set a new benchmark for long-term, multi-session conversational memory, achieving the highest overall score on LongMemEval-s. This benchmark is designed to stress-test memory frameworks beyond simple lookups, evaluating how systems handle evolving identity, preferences, timelines, and knowledge across hundreds of sessions.
Category | Cortex AI* |
|---|---|
Single-session-user | 100% |
Single-session-assistant | 100% |
Single-session-preference | 80.00% |
Knowledge-up-to-date | 94.87% |
Temporal-reasoning | 90.97% |
Multi-session | 76.69% |
Overall | 90.23% |
Cortex AI achieved 90.23% overall accuracy, with significant performance in single-session-user and single-session-assistant (perfect score), temporal reasoning, preference understanding, and knowledge updates. These categories represent the hardest and most production-critical failure modes for AI agents, making Cortex AI's performance particularly relevant for real-world SaaS applications.
*Cortex AI evaluated using Gemini 3.0 Pro.
Which Memory Backend Fits: Vector, Graph, or Hybrid?
Choosing the right store depends on your workload profile.
Backend | Strengths | Trade-offs |
|---|---|---|
Vector (e.g., Vespa, Redis) | Sub-millisecond latency, scales to billions of docs, great for semantic similarity | Limited relational reasoning |
Graph-Augmented | Explicit edges for temporal and relational queries | Higher latency, more complex ops |
Hybrid | Combines vector speed with graph semantics | Operational complexity |
Some vector databases deliver sub-millisecond latency by running vector search, filtering, scoring, and model inference directly on content nodes -- eliminating network hops. They can support continuous data ingestion without costly index rebuilds, making them suitable for RAG pipelines that need real-time freshness.
Other vector databases can sustain high vector insertions per second at high precision and offer significantly faster query speed than some open benchmarks.
Graph-augmented layers add reasoning when relationships trump raw similarity. Cortex AI, for instance, demonstrated 90.97% accuracy in temporal reasoning on LongMemEval-s, highlighting the importance of explicit edges for complex queries.
Key takeaway: Start with a vector store for speed and scale; layer graph semantics only when relational or temporal reasoning justifies the overhead.
How Does Personalization Ride on Top of Memory?
Memory without personalization is just storage. The value comes when the system adapts to each user.
Graph-based retrieval enriches personalization by integrating structured user knowledge directly into the retrieval process. PGraphRAG leverages user-centric knowledge graphs to deliver meaningful personalization even in cold-start scenarios where user history is sparse.
Bandit re-ranking optimizes which memories surface. PURPLE, a contextual bandit framework, casts retrieval-augmented LLM personalization as a bandit problem, adaptively selecting user records beyond static heuristics. It consistently outperforms retrieval-augmented baselines.
Tenant-level learning is essential for B2B SaaS. Cortex's memory improves over time: the system learns how individual users behave -- what formats they prefer, what content types they favor, and how they usually ask questions. "It makes every interaction feel more personal. Responses start to feel tailored instead of generic, which drives higher engagement, better results, and user delight" (Cortex Docs).

How to Scale Agentic Memory Safely in Production
Autonomous agents introduce new risk surfaces. Eighty percent of organizations say they have encountered risky behaviors from AI agents, including improper data exposure and unauthorized system access.
Governance essentials:
SOC 2 and encryption -- Any memory layer handling customer data should meet SOC 2 requirements with strong encryption at rest and in transit.
Detailed security review -- Forrester ensures third-party AI tools go through a detailed security review before deployment.
Auditability -- Systems should make it easy for developers to build context-aware agents by eliminating complex memory infrastructure management while providing full control over what the AI agent remembers.
Risk categories to monitor:
Chained vulnerabilities -- A flaw in one agent cascades across tasks.
Cross-agent task escalation -- Malicious agents exploit trust mechanisms.
Untraceable data leakage -- Autonomous agents exchanging data without oversight obscure leaks.
Key takeaway: Bake safety and security into the memory layer from the outset; retrofitting governance is far more expensive.
Key Takeaways & Next Steps
Extended memory is non-negotiable for SaaS agents that live longer than a single session.
Extraction/update loops keep storage lean and costs low.
Vector backends handle scale; add graph semantics only when relational reasoning justifies complexity.
Personalization turns memory into a competitive moat -- users stay when the product remembers them.
Governance must be architected in, not bolted on.
Cortex offers a memory-first context and retrieval platform that bundles these capabilities -- self-improving memory, native SaaS integrations, SOC 2 compliance, and sub-200ms latency -- and is validated by its industry-leading performance on LongMemEval-s. If you're building agents that need to remember, adapt, and improve, explore Cortex to see how a purpose-built memory layer accelerates your roadmap.
Frequently Asked Questions
What does it mean to extend LLM memory?
Extending LLM memory involves providing large language models with access to external facts beyond their native context window, allowing them to recall and adapt to past interactions, thus simulating coherent, goal-directed behavior.
Why do SaaS LLMs hit the context wall?
SaaS LLMs hit the context wall due to token limits, which increase costs, erode customer trust when assistants fail to recall past interactions, and limit the effectiveness of generative AI, which needs memory to transition from reactive to proactive roles.
What are the architectural patterns to extend memory?
Three main patterns are used: Extraction/Update Loops for evolving conversations, Virtual Context Paging for document analysis, and Closed-Loop Retrieval for complex Q&A, each providing durable context for AI agents.
How does Cortex enhance memory for AI agents?
Cortex enhances memory by treating it as a first-class primitive, offering persistent, user-specific, and tenant-aware memory that allows AI agents to remember interactions and adapt responses, improving relevance and personalization over time.
What are the governance essentials for scaling agentic memory?
Governance essentials include SOC 2 compliance, strong encryption, detailed security reviews, and auditability to prevent risks like data leakage and unauthorized access, ensuring safe deployment of autonomous agents.