
Mem0 vs Cortex for Long-Term LLM Memory
Cortex provides real-time memory infrastructure that learns and adapts with each interaction, while Mem0 uses a two-phase extract/update pipeline achieving 66.9% accuracy on LongMemEval benchmarks. Cortex's hybrid graph architecture on Convex enables instant context updates and self-improving personalization that adapts to user preferences, making it the stronger choice for production agents requiring continuous learning and multi-tenant isolation.
At a Glance
• Mem0 achieves 26% higher response accuracy than OpenAI Memory with 0.2s median latency through selective retrieval
• Cortex offers fully managed memory infrastructure with real-time updates, eliminating separate vector database and graph service requirements
• Both platforms deliver 90% token savings compared to full-context methods, directly reducing LLM API costs
• Cortex's built-in reasoning engine handles multi-step queries and parallel searches without external tooling
• Enterprise features include SOC 2 compliance (Mem0), HIPAA-readiness, and hierarchical multi-tenancy support (both platforms)
• Cortex pricing starts at $400/month for 10M tokens, while Mem0 requires additional infrastructure costs for self-hosted deployments
Long-term memory is the missing ingredient that separates a clever chatbot from a genuinely useful AI agent. Without it, every session starts from scratch, context vanishes, and users repeat themselves endlessly. This post compares Mem0 and Cortex head to head, examining architecture, benchmarks, enterprise readiness, and total cost of ownership to help you choose the right memory layer for production.
Why Do LLM Agents Need Long-Term Memory in 2026?
Stateless agents forget. They lose track of user preferences, ignore past decisions, and force customers to re-explain their situations every time they return. That friction erodes trust and undermines the promise of AI-driven personalization.
The problem is widespread. According to McKinsey's 2025 State of AI report, "almost all survey respondents say their organizations are using AI, and many have begun to use AI agents" (McKinsey). Yet most deployments still treat each conversation as an isolated event.
Cortex addresses this gap directly. It is "plug-and-play memory infrastructure" that "powers intelligent, context-aware retrieval for any AI app or agent" (Cortex Docs). Rather than bolting memory on as an afterthought, Cortex bakes it into the retrieval layer so that every interaction teaches the system something new.
Mem0 also targets the long-term memory challenge. Benchmarks show that OpenAI Memory "is fast, but often misses multi-hop details" (Mem0 Benchmark). Mem0 aims to fix that with a selective retrieval approach, but the two platforms differ sharply in how they store, update, and personalize memories.
Key takeaway: A dedicated memory layer is no longer optional if you want agents that feel intelligent over weeks and months, not just minutes.
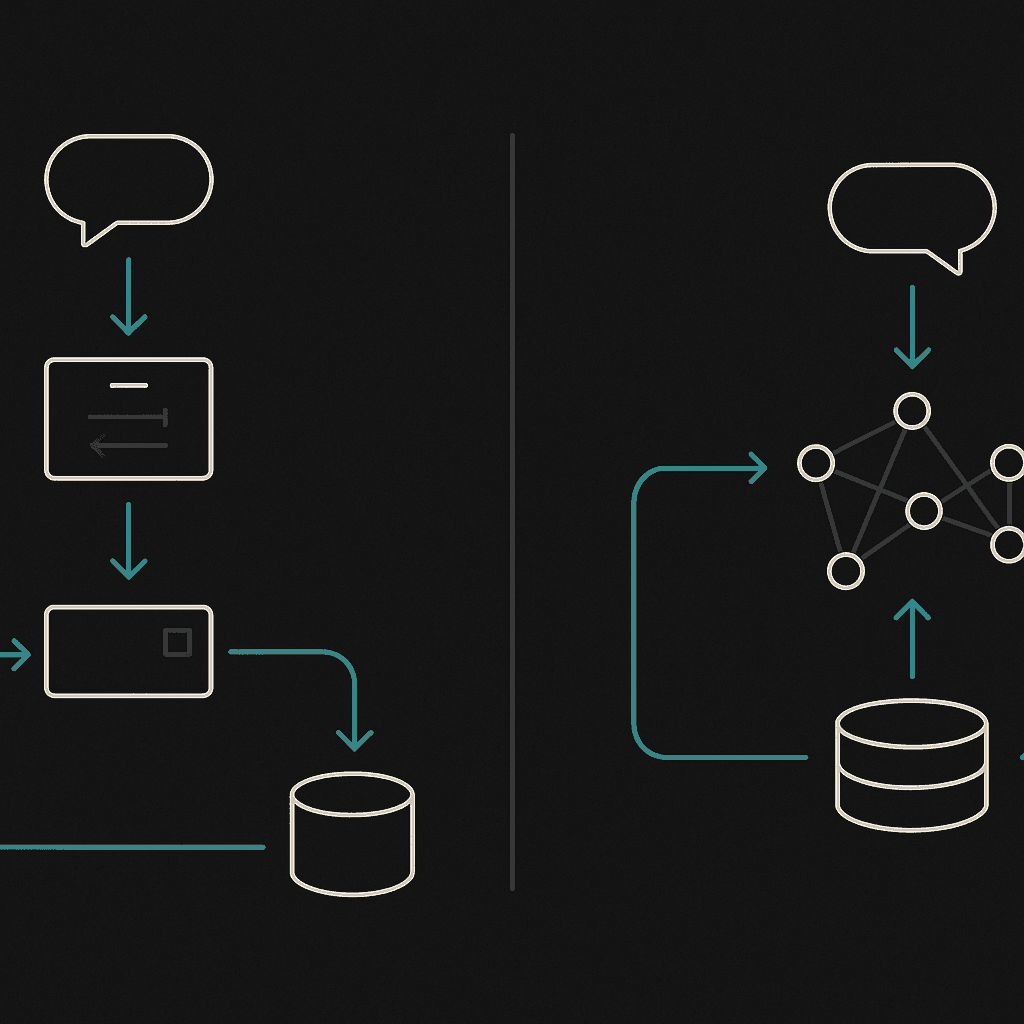
How Do Mem0 and Cortex Store & Retrieve Memory?
Architecture determines how quickly context updates, how accurately the system recalls facts, and how much operational overhead you carry.
Mem0's Two-Phase Extraction & Update Loop
Mem0 uses a pipeline split into two stages:
Extraction Phase - The system ingests three context sources (the latest exchange, a rolling summary, and the most recent messages) and uses an LLM to extract candidate memories (Mem0 Research).
Update Phase - Each new fact is compared to similar entries in the vector database. The LLM then chooses one of four operations: ADD, UPDATE, DELETE, or NOOP (Mem0 Research).
This design keeps token counts low and latency manageable, but it introduces a separate update hop after every chat round.
Cortex's Real-Time Hybrid Graph
Cortex takes a different path. It is "built on Convex for instant updates across all clients. No polling, no stale data" (Cortex Memory Docs). New information streams directly into the hybrid retrieval graph without a dedicated update phase, so context stays fresh and every query refines the system.
Additional architectural highlights:
Semantic Memory - Store and retrieve memories using natural language; AI-powered embeddings find relevant context automatically.
Isolated Memory Spaces - Strict user/agent boundaries with optional collaboration.
Hierarchical Context Propagation - Designed for multi-agent systems where parent agents share context with child agents.
Optional Graph Integration - Neo4j or Memgraph for relationship-rich context.
The result is a platform that learns continuously rather than in discrete write cycles.
Performance & Latency: What Do the Benchmarks Say?
Numbers matter when SLAs are on the line. The LongMemEval benchmark measures five core abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention.
As per Cortex's preliminary benchmark, it achieved the highest overall score on LongMemEval—with significant gains in temporal reasoning, knowledge updates, and user-preference understanding. These categories are often considered the hardest and most useful in real-world scenarios.
Category | Cortex AI* | Supermemory* | Zep** | Full-context** | Mem0 | Letta |
|---|---|---|---|---|---|---|
Single-session-user | 100% | 98.57% | 92.9% | 81.4% | - | - |
Single-session-assistant | 100% | 98.21% | 80.4% | 94.6% | - | - |
Single-session-preference | 80.00% | 70.00% | 56.7% | 20.0% | - | - |
Knowledge-up-to-date | 94.87% | 89.74% | 83.3% | 78.2% | - | - |
Temporal-reasoning | 90.97% | 81.95% | 62.4% | 45.1% | - | - |
Multi-session | 76.69% | 76.69% | 57.9% | 44.3% | - | - |
Overall | 90.23% | 85.2% | 71.2% | 60.2% | - | - |
Cortex AI* and Supermemory* were evaluated using Gemini 3.0 Pro. Zep** and Full-context** baselines were evaluated using GPT-4o. No public results are available for Mem0 & Letta on LongMemEval.
Cortex AI sets a new benchmark with 90.23% overall accuracy, outperforming the previous current best by +5 points. The most significant gains appear in single-session-user & single-session-assistant (perfect score), temporal reasoning (10%), preference understanding (+10%), and knowledge updates (5%). LongMem-Eval serves as the ultimate stress test for long-context retrieval, pushing memory frameworks beyond simple needle-in-a-haystack lookups (common in LoCoMo).
LongMemEval also reveals that "commercial chat assistants and long-context LLMs showing a 30% accuracy drop on memorizing information across sustained interactions" (arXiv LongMemEval). This underscores how quickly recall degrades without a purpose-built layer.
Cortex is designed to address this challenge. Rather than optimizing a single accuracy metric, it "automatically handles very complex questions using an in-built reasoning engine that runs multiple parallel searches, figures out the best sequence, and returns complete answers for sophisticated workflows" (Cortex Multi-Step). For agents that need to chain multiple retrievals, sequential reasoning, and parallel processing, Cortex's architecture is built to manage complex queries.
While production chat assistants often aim for sub-2-second SLAs, the difference in platforms emerges when layering in personalization, multi-tenancy, and continuous learning, areas where Cortex is designed to excel.
How Does Each Platform Handle Security, Personalization & Multi-Tenancy?
Enterprise buyers care about compliance, tenant isolation, and whether the system actually gets smarter per user. Mem0 is "SOC 2 compliant, HIPAA-ready, and trusted by enterprises to protect sensitive memory and data across AI workflows" (Mem0 Security). It offers zero-trust access controls, BYOK encryption, and audit logs. Cortex also supports multi-tenancy out of the box. Version 0.28.0 introduced "Basic Template & Multi-Tenancy" (Cortex Memory Docs), enabling strict tenant isolation with hierarchical context propagation for complex organizational structures.
Why Self-Improving Personalization Matters
Cortex's memory "improves over time. The system learns how individual users behave - what formats they prefer (e.g. tables, summaries), what content types they favor (e.g. spreadsheets, slides), and how they usually ask questions" (Cortex Self-Improving).
Consider a sales team assistant. Alex, a rep, prefers bullet points and XLSX files. Over time, Cortex recognizes this pattern and automatically responds in bullet points while prioritizing spreadsheet sources. That level of adaptation is baked into the retrieval layer, not tacked on via prompt engineering.
"It makes every interaction feel more personal. Responses start to feel tailored instead of generic, which drives higher engagement, better results, and user delight."
Mem0 offers persistence across users and agents, but the self-improving loop is less tightly integrated into the retrieval path.
Where Do Developers Choose Cortex Over Mem0?
Real-world fit depends on the use case. Here are scenarios where Cortex tends to win:
Agentic workflows with multi-step reasoning - Cortex's reasoning engine breaks complex queries into logical sub-tasks, handles sequential and parallel processing, and preserves context across steps. A manager can ask, "Summarize all Q1 sales calls, extract the action items, and draft a follow-up plan" and receive a coherent answer without manually decomposing the request (Cortex Multi-Step).
Marketing, sales, and customer service agents - McKinsey estimates that "agentic AI will power more than 60 percent of the increased value that AI is expected to generate from deployments in marketing and sales" (McKinsey Growth). These domains demand personalization, long-term memory, and fast context retrieval - Cortex's core strengths.
Teams that want a managed, self-improving layer - Zep's comparison notes that platforms like Mem0 require "owning the plumbing" (Zep vs Mem0). Cortex abstracts away vector stores, embedding selection, and parsing pipelines, letting developers focus on the agent logic.
Mem0 remains a solid choice when you need a lightweight, developer-controlled memory component and are comfortable managing storage, retrieval, and monitoring yourself.

What Is the Real Total Cost of Ownership?
Pricing models vary, and hidden costs lurk in token overhead, throttling, and operational maintenance.
Cortex Pricing
Tier | Monthly Cost | Highlights |
|---|---|---|
Pro | $400 | Up to 10 M tokens ingested/mo, up to 5 tenants, community support |
Scale | $5,000 | Unlimited memories, unlimited tenants, priority Slack support |
Source: Cortex Pricing
Cortex bundles ingestion, retrieval, and memory management into a single platform, eliminating the need to provision separate vector databases, graph services, or rerankers.
Mem0 Considerations
Mem0 offers managed infrastructure, but "doesn't magically remove ops work - you still need to run storage, retrieval, and monitoring, which adds overhead" (Pieces AI Memory Review). If you self-host, factor in DevOps time for vector store tuning, backup, and scaling.
Token economics also matter. Mem0 achieves 90 % savings in token usage compared to full-context methods (Mem0 Research), which keeps LLM API bills low. Cortex's integrated architecture similarly minimizes redundant context stuffing, and its reasoning engine avoids the ballooning token counts that plague naive RAG setups.
LLM API Costs (Reference)
Provider | Model | Input (per 1 M tokens) | Output (per 1 M tokens) |
|---|---|---|---|
OpenAI | GPT-5.2 | $1.75 | $14.00 |
Anthropic | Claude Opus 4.5 | $5.00 | $25.00 |
DeepSeek | V3.2 (non-thinking) | $0.28 | $0.42 |
Source: BinaryVerseAI
Choosing an efficient memory layer directly reduces these costs by trimming prompt tokens and caching stable context.
Key takeaway: Evaluate total cost - platform fees plus LLM usage plus ops overhead - not just the sticker price.
Choosing the Right Memory Layer for 2026 and Beyond
Both Mem0 and Cortex solve the stateless-agent problem, but they target different developer profiles:
Factor | Mem0 | Cortex |
|---|---|---|
Architecture | Two-phase extract/update loop | Real-time hybrid graph on Convex |
Self-improving personalization | Limited | Native, user-level learning |
Multi-tenancy | Supported | Hierarchical, context-propagating |
Reasoning engine | Separate tooling required | Built-in multi-step retrieval |
Ops overhead | Moderate (self-host) or managed | Fully managed |
Cortex "doesn't just fetch documents. It learns, adapts, and gets smarter with time" (Cortex Docs). That philosophy aligns with the direction enterprise AI is heading: systems that treat memory as a first-class primitive, not a bolt-on.
"With every new interaction, Cortex supplies the right context so your agent avoids past mistakes and gets better over time."
If you need a memory component you fully control and are willing to manage the infrastructure, Mem0 delivers solid accuracy and low latency. If you want a self-improving, real-time memory layer that scales from prototype to production without babysitting, Cortex is the stronger bet for 2026 and beyond.
Explore Cortex to see how persistent, adaptive memory can transform your AI agents.
Frequently Asked Questions
What is the main difference between Mem0 and Cortex for LLM memory?
The main difference lies in their architecture and approach to memory. Mem0 uses a two-phase extraction and update loop, while Cortex employs a real-time hybrid graph for instant updates, offering superior personalization and continuous learning.
Why is long-term memory important for LLM agents?
Long-term memory is crucial for LLM agents as it allows them to retain context, user preferences, and past interactions, reducing friction and enhancing personalization. This capability is essential for creating intelligent, adaptive AI agents.
How does Cortex handle personalization differently from Mem0?
Cortex integrates self-improving personalization directly into its retrieval layer, learning user preferences over time and adapting responses accordingly. This contrasts with Mem0, where personalization is less tightly integrated into the retrieval process.
What are the performance benchmarks for Mem0 and Cortex?
Mem0 shows strong performance in benchmarks like LongMemEval, but Cortex excels in handling complex queries with its multi-step reasoning engine, avoiding latency spikes and providing more comprehensive answers.
What are the cost considerations when choosing between Mem0 and Cortex?
Cortex offers a managed platform that includes ingestion, retrieval, and memory management, reducing operational overhead. Mem0, while cost-effective in token usage, requires additional DevOps resources for managing storage and retrieval infrastructure.