
How to Share LLM Memory Across AI Agents
Sharing LLM memory across AI agents means creating a persistent knowledge layer that multiple agents can access and update, enabling them to build on each other's work without re-processing information. This involves using architectures like KV-cache sharing for 7.8x speedups or external vector stores that maintain context beyond single sessions.
At a Glance
Shared memory eliminates redundant processing when multiple agents collaborate, reducing latency by up to 7.8x with KVCOMM framework
Two main approaches exist: cache-level sharing (C2C, KVCOMM) for same-infrastructure agents and external stores (vector/graph DBs) for cross-model persistence
MemoryAgentBench evaluates four core competencies: accurate retrieval, test-time learning, long-range understanding, and selective forgetting
Production implementations like Cortex provide hierarchical context propagation with strict user/agent boundaries and real-time sync capabilities
Memory design requires balancing short-term session context with long-term knowledge retention through summarization and selective pruning
When multiple AI agents collaborate on a task, each one typically operates in its own context window with no visibility into what the others know. The result is repeated work, lost continuity, and inconsistent answers. Sharing memory changes that equation.
Teams building production agents face three interrelated challenges: latency, personalization, and accuracy. Latency spikes when every agent must re-process the same documents. Personalization suffers when user preferences cannot follow a conversation from one agent to another. Accuracy degrades when relevant facts sit outside the current context window.
This guide walks through the architectures and patterns that let you move memory out of isolated silos and into a shared layer that any agent can access.
What Does It Mean to Share LLM Memory Across Agents?
Agent memory refers to an AI agent's ability to persist and recall information from previous interactions. When that capability extends beyond a single model instance, agents can hand off context, build on each other's discoveries, and avoid repeating work.
Memory in this context is persistent knowledge retained by an agent across sessions. It differs from the ephemeral data that lives only for one request.
AI agents are systems capable of pursuing and achieving goals by harnessing the reasoning capabilities of large language models to plan, observe, and execute actions, according to Redis documentation. Sharing memory means giving those systems a common pool of facts, preferences, and state so they can coordinate without constant re-prompting.
Why Share Memory: Benefits & Critical Use Cases
Large language models stream text fluidly, but they forget once the conversation exceeds their context window. A purpose-built memory layer prevents that forgetting entirely.
Memory allows AI agents to learn from past interactions, retain information, and maintain context, leading to more coherent and personalized responses.
Agentic memory is emerging as a key enabler for LLMs to maintain continuity, personalization, and long-term context in extended user interactions, which are critical capabilities for deploying LLMs as truly interactive and adaptive agents.
Common scenarios where shared memory delivers value:
Multi-step customer support where one agent triages, another investigates, and a third resolves
Research workflows in which a planning agent defines questions and specialist agents retrieve answers
Personalized assistants that remember user preferences regardless of which backend model responds

What Architectures Enable Shared Memory Across Agents?
Two broad families dominate the landscape: low-level cache communication and external persistent stores.
Cache-to-Cache (C2C) uses a neural network to project and fuse the source model's KV-cache with that of the target model to enable direct semantic transfer. This approach keeps communication inside the inference layer.
KVCOMM is a training-free framework that enables efficient prefilling in multi-agent inference by reusing KV-caches and aligning cache offsets of overlapping contexts under diverse prefix contexts.
In Azure AI, agentic retrieval is a new multi-query pipeline designed for complex questions posed by users or agents in chat and copilot apps, intended for RAG patterns and agent-to-agent workflows.
KVCOMM achieves "over 70% reuse rate across diverse multi-agent workloads, including retrieval-augmented generation, math reasoning, and collaborative coding tasks, all without quality degradation," according to OpenReview research. The same work reports up to 7.8x speedup compared to the standard prefill pipeline.
KV-Cache & Cache-to-Cache Links
C2C achieves 8.5 to 10.5 percent higher average accuracy than individual models and delivers an average 2.0x speedup in latency over text-based communication.
Q-KVComm achieves 5 to 6x compression ratios while maintaining semantic fidelity, with coherence quality scores above 0.77 across all scenarios.
KVCOMM is training-free and uses an anchor pool to dynamically adapt to different user requests and context structures, representing a substantial advancement in KV-cache sharing efficiency without recomputation overhead.
Approach | Compression | Latency Gain | Training Required |
|---|---|---|---|
C2C | N/A | 2x | Yes (neural fuser) |
KVCOMM | 70%+ reuse | Up to 7.8x | No |
Q-KVComm | 5-6x | Varies | No |
Trade-offs exist. Cache-level sharing demands compatible model architectures and careful offset alignment. It excels when agents run on the same infrastructure and share overlapping contexts.
External Vector & Graph Memories
The Microsoft 365 Copilot Retrieval API offers a streamlined solution for RAG without the need to replicate, index, chunk, and secure data in a separate index.
Azure Cosmos DB supports both vector indexing for semantic similarity and full-text indexing for keyword-based retrieval.
MemR3 transforms retrieval into a closed-loop process: a router dynamically switches between Retrieve, Reflect, and Answer nodes while a global evidence-gap tracker maintains what is known and what is still missing.
External stores suit scenarios where agents run on different machines, use different model families, or need to persist memory beyond a single session.
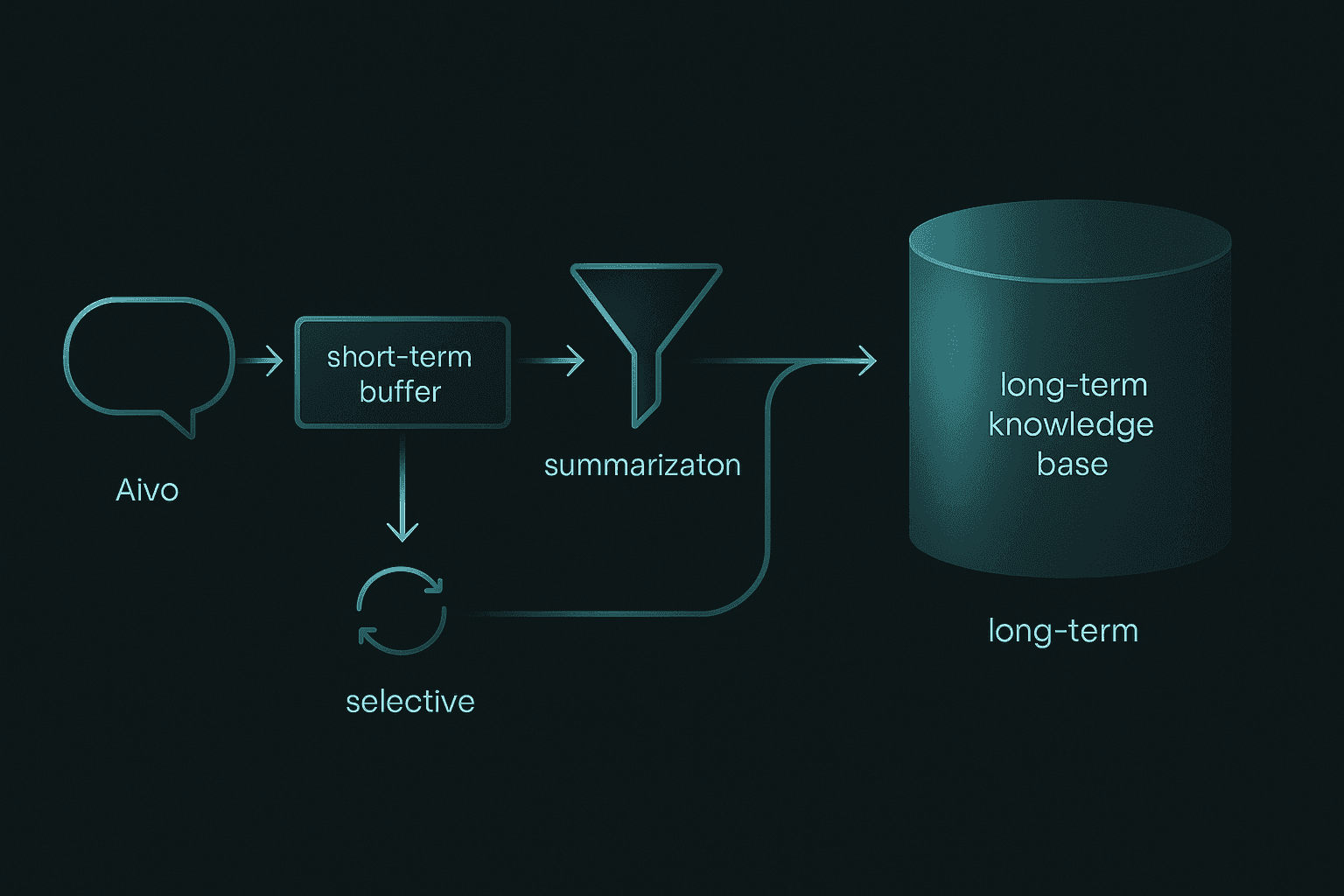
How Do You Design Memory-Friendly Agent Patterns?
Short-term memory tracks the current session's conversation and maintains immediate context for ongoing interactions. Long-term memory retains distilled knowledge across sessions.
Cortex provides a robust multi-tenant architecture with hierarchical tenant support, enabling you to build secure, scalable B2B platforms.
Agentic AI represents a disruptive paradigm shift that requires organizations to rethink how to build, deliver, and operate their systems.
Key design decisions:
Partition by tenant to enforce data isolation
Scope memories by session or user to control retrieval breadth
Set retention policies that balance recall with cost
Balancing Short-Term vs Long-Term Stores
Researchers have identified four core competencies essential for memory agents: accurate retrieval, test-time learning, long-range understanding, and selective forgetting.
Reflective Memory Management (RMM) shows more than 10 percent accuracy improvement over the baseline without memory management on the LongMemEval dataset.
Practical tactics:
Summarization: Compress older turns into topic-level summaries
Decay weighting: Prioritize recent interactions using exponential weighted averages
Selective forgetting: Prune facts that conflict with newer, authoritative updates
Key takeaway: Treat memory as a living resource that evolves rather than an append-only log.
How Major Platforms Implement Shared Memory
Platform | Memory Model | Multi-Tenant | Notable Feature |
|---|---|---|---|
Vertex AI Memory Bank | Long-term, session-scoped | Data isolation per identity | Asynchronous generation, ADK integration |
Azure Foundry Agent Service | Managed long-term | Azure-native isolation | Extraction, consolidation, retrieval phases |
Redis | Vector + semantic | Framework-agnostic | Fastest benchmarked vector search |
Cortex | Self-improving hybrid | Hierarchical tenant/sub-tenant | Real-time sync, strict boundaries |
Vertex AI Agent Engine Memory Bank lets you dynamically generate long-term memories based on users' conversations with your agent.
Memory Bank includes features such as memory generation, extraction, consolidation, asynchronous generation, multimodal understanding, managed storage and retrieval, data isolation across identities, and automatic expiration.
New Google Cloud customers receive $300 in free credits to run, test, and deploy workloads.
Cortex differs by treating memory as a first-class primitive rather than an add-on. It combines hierarchical context propagation for multi-agent systems with strict user and agent boundaries, allowing optional collaboration when needed.
Which Benchmarks Matter for Memory Systems?
MemoryAgentBench is a new benchmark specifically designed for memory agents. It evaluates four competencies: accurate retrieval, test-time learning, long-range understanding, and selective forgetting.
Practitioners have evaluated memory layers under four constraints: factual consistency after 600-turn chats, sub-second responsiveness, token efficiency, and reasoning quality on single-hop, multi-hop, temporal, and open-domain questions.
MemR3 surpasses strong baselines on LLM-as-a-Judge score, improving existing retrievers with an overall improvement on RAG (+7.29 percent) and Zep (+1.94 percent) using the GPT-4.1-mini backend.
When selecting a benchmark, match it to your workload:
Long-context retention: MemoryAgentBench
Production chat SLA: Mem0 benchmark suite
Retrieval quality: MemR3 evaluation framework
Quick Start: Sharing Memory with the Cortex SDK
Cortex requires only three commands to give your AI agents persistent memory.
Install the SDK and authenticate with your API key
Create a tenant that represents your organization or customer
Store and retrieve memories using natural language queries
LangGraph's lightweight message-passing architecture allows flexible, dynamic coordination among agents, crucial for rapid retrieval tasks. Cortex integrates with LangGraph and similar frameworks through its REST and Python APIs.
The workflow achieves notable gains in efficiency and accuracy, with a 4x reduction in retrieval latency (from 43 seconds to 11 seconds) and a 7 percent increase in Top-10 accuracy over traditional hybrid baselines.
Memory is dynamic and user-specific within Cortex. It updates automatically through conversation, queries, and usage, giving your app the ability to learn, remember, and adapt.
Key Takeaways
Cortex doesn't just fetch documents. It learns, adapts, and gets smarter with time, as described in the Cortex documentation.
Hierarchical context propagation for multi-agent systems enables agents to inherit and share context without manual wiring, according to Cortex Memory documentation.
Core practices to remember:
Persist memory outside any single model to enable true collaboration
Use KV-cache sharing for latency-critical, same-infrastructure workloads
Rely on external vector or graph stores for cross-model, cross-session continuity
Design retention policies that balance recall, cost, and selective forgetting
Benchmark against competencies that match your production constraints
For teams building AI agents that must remember, personalize, and coordinate, Cortex offers a self-improving memory layer that handles ingestion, retrieval, and multi-tenant isolation out of the box. Explore the SDK to see how shared memory can transform your agent workflows.
Frequently Asked Questions
What is LLM memory sharing across AI agents?
LLM memory sharing allows AI agents to access a common pool of information, enabling them to coordinate tasks, build on each other's discoveries, and avoid redundant work. This shared memory enhances collaboration and efficiency among agents.
Why is sharing memory important for AI agents?
Sharing memory is crucial for AI agents as it improves personalization, reduces latency, and enhances accuracy by allowing agents to retain and recall information across sessions. This leads to more coherent and contextually aware interactions.
What architectures support shared memory in AI agents?
Shared memory in AI agents can be supported by cache-to-cache communication and external persistent stores. Cache-to-cache uses neural networks for semantic transfer, while external stores like vector and graph memories provide cross-session continuity.
How does Cortex facilitate memory sharing for AI agents?
Cortex offers a self-improving memory layer that integrates with AI agents to provide persistent memory, enabling them to remember past interactions and personalize responses. It supports multi-tenant architectures and real-time synchronization.
What are the benefits of using Cortex for AI memory management?
Cortex provides a robust memory management system that enhances AI agent performance by enabling persistent memory, personalization, and hierarchical context propagation. It reduces latency and improves accuracy without manual infrastructure management.
Sources
https://openreview.net/pdf/81561154949bf17e7f12ee6dc0485c10a2415686.pdf
https://learn.microsoft.com/en-us/azure/ai-foundry/agents/concepts/agent-memory?view=foundry
https://openreview.net/pdf/2b14e3fecd25cd9511348c6a9ad470c2a2161634.pdf
https://learn.microsoft.com/en-us/azure/cosmos-db/gen-ai/agentic-memories
https://redis.io/blog/build-smarter-ai-agents-manage-short-term-and-long-term-memory-with-redis/
https://learn.microsoft.com/en-us/azure/search/agentic-retrieval-overview
https://docs.cloud.google.com/agent-builder/agent-engine/memory-bank/overview
https://docs.cloud.google.com/agent-builder/agent-engine/memory-bank/quickstart