
How to Improve LLM Memory Recall Accuracy
Improving LLM memory recall accuracy requires combining cognitive strategies, architectural innovations, and hybrid retrieval systems. Cognitive techniques like chunking reduce working memory overload by grouping related information. Memory-first architectures like Titans introduce neural long-term memory modules that maintain context across millions of tokens, while hybrid RAG systems boost recall metrics by 7-18% through combined dense-sparse search.
Key Facts
• Memory bottlenecks mirror human cognition - LLMs face working memory constraints similar to humans, dropping facts mid-conversation when overloaded
• Hybrid retrieval delivers measurable gains - Combining dense and sparse search increases Recall@5 by 7.2% with only 201ms additional latency
• Fact-verification reduces hallucinations by 67% - Cross-checking outputs against multiple knowledge sources achieves 92% factual accuracy
• Memory-first architectures outperform baselines - Systems like Memoria significantly reduce token overhead while maintaining context-aware, consistent dialogue
• Standardized benchmarks expose critical gaps - MemAE framework tests four core competencies: accurate retrieval, test-time learning, long-range understanding, and conflict resolution
Large language models can draft emails, summarize legal briefs, and write code, yet they routinely forget facts they were told two paragraphs earlier. That forgetfulness is not a quirk; it is a structural limitation rooted in how models hold information during inference. Improving LLM memory recall accuracy is now one of the most consequential challenges facing teams that ship AI agents and assistants.
This guide examines the problem from three angles: the cognitive science that explains why recall degrades, the emerging architectures that embed persistent memory into the model loop, and the retrieval strategies that feed the right context back at the right time. Each section draws on peer-reviewed research, production benchmarks, and real-world deployment lessons so you can move from theory to implementation.
Why Does Memory Recall Matter for Large Language Models?
Memory recall accuracy determines whether an AI agent can hold a coherent, multi-turn conversation or whether it hallucinates details it should already know. When a model fails to retrieve information it was given moments ago, users lose trust, and downstream automation breaks.
Recent benchmarks for LLM agents have primarily focused on planning and execution, while another critical component -- memory -- has far fewer evaluation frameworks. That gap matters because memory underpins every competency agents need: accurate retrieval, test-time learning, long-range understanding, and conflict resolution.
From a cognitive perspective, working memory is integral to human reasoning, serving as the system that temporarily holds and manipulates information for complex tasks like learning and comprehension. LLMs face a parallel constraint: despite increased context windows, they still struggle to hold and process information effectively under complex task conditions.
"Agentic memory is emerging as a key enabler for large language models to maintain continuity, personalization, and long-term context in extended user interactions."
-- arXiv
Without robust memory, models cannot evolve with users, recall prior interactions, or adapt responses over time. The remainder of this post explains how to close that gap.
Where Do LLMs Fall Short on Memory and Accuracy?
Even the largest models exhibit predictable failure modes when memory is involved.
Working-memory bottlenecks. Despite increased model size, LLMs still face significant challenges in holding and processing information effectively, especially under complex task conditions. Prompting strategies can help, but they do not eliminate the underlying constraint.
False-memory formation. Human cognition offers a cautionary parallel. Perception and memory are imperfect reconstructions of reality, prone to factors that result in false memories. LLMs exhibit analogous behavior: they generate plausible but incorrect details, especially when context is sparse or contradictory.
Reality-monitoring failures. Mounting evidence identifies the anterior prefrontal cortex as playing a key role in distinguishing internally from externally generated information. LLMs lack an equivalent circuit. They cannot reliably tell whether a fact came from the prompt, their training data, or thin air, which contributes to hallucinations.
Failure Mode | Cognitive Parallel | LLM Symptom |
|---|---|---|
Working-memory overload | Limited human slot capacity | Drops facts mid-conversation |
False-memory generation | Imagery-induced distortions | Fabricates plausible details |
Reality-monitoring error | Anterior PFC dysfunction | Confuses prompt with training data |
Key takeaway: Memory failures in LLMs are not random; they mirror well-studied cognitive bottlenecks, which means proven human strategies can inform solutions.
Cognitive Strategies: Chunking, Schemas & Working Memory
Cognitive science has spent decades studying how humans compensate for limited working memory. Three concepts translate directly to LLM design.
Chunking
Chunking is the recoding of smaller units of information into larger, familiar units. When humans chunk a phone number into three groups instead of ten digits, they free slots for other information. The same principle applies to prompt engineering and data preprocessing:
Group related facts into labeled sections before feeding them to a model.
Place chunks early in the context; chunks at the end of the list do not improve recall of other material.
Use unique identifiers so the model can reference a chunk by its first element.
Schemas
A schema is a cognitive structure for representing and retrieving classes of typical situations. In LLM terms, schemas are templated prompts that cue the model to expect certain relationships. Providing a schema reduces ambiguity and primes the model's retrieval path.
Semantic scaffolding
Long-term memory knowledge, such as semantic knowledge, supports the temporary maintenance of verbal information in working memory. Semantically related items enjoy a recall advantage over unrelated items. For LLM applications, this means structuring retrieved documents by topic clusters rather than by recency alone.
Key takeaway: Chunking, schemas, and semantic grouping are low-cost interventions that can raise recall accuracy before you touch the model architecture.
New Memory-First Architectures: Titans, Memoria & MEM1
When prompt engineering reaches its limits, architecture changes become necessary. Three research systems illustrate the current frontier.
Titans
Titans introduces a novel neural long-term memory module that, unlike the fixed-size vector or matrix memory in traditional RNNs, acts as a deep neural network. The module summarizes past information and feeds that summary back into the context before attention runs.
Surprise-based gating: Titans uses a surprise signal based on the model's internal error. When the incoming token diverges sharply from memory, the system writes more aggressively.
Benchmark performance: Titans architectures outperform state-of-the-art linear recurrent models such as Mamba-2 and Transformer++ baselines across language modeling, common-sense reasoning, and needle-in-haystack tasks.
Memoria
Memoria is a scalable agentic memory framework that integrates dynamic session-level summarization with a weighted knowledge graph. The architecture ensures context-aware, consistent, and evolving dialogue while significantly reducing token overhead by avoiding full-history prompting.
Memoria's retrieval module enables the LLM to recall relevant past information when a user returns after a pause, whether the gap is a few minutes or several days.
MEM1
MEM1 is an end-to-end reinforcement learning framework that enables agents to operate with constant memory across long multi-turn tasks. In benchmarks, MEM1-7B improves performance by 3.5× while reducing memory usage by 3.7× compared to Qwen2.5-14B-Instruct on a 16-objective multi-hop QA task.
Architecture | Core Innovation | Best-Fit Use Case |
|---|---|---|
Titans | Neural long-term memory module | Ultra-long context (>2M tokens) |
Memoria | Weighted knowledge graph + session summaries | Personalized conversational agents |
MEM1 | RL-trained memory consolidation | Multi-turn retrieval tasks |
Key takeaway: Memory-first architectures treat recall as a trainable objective, not an afterthought, enabling agents that improve with use.
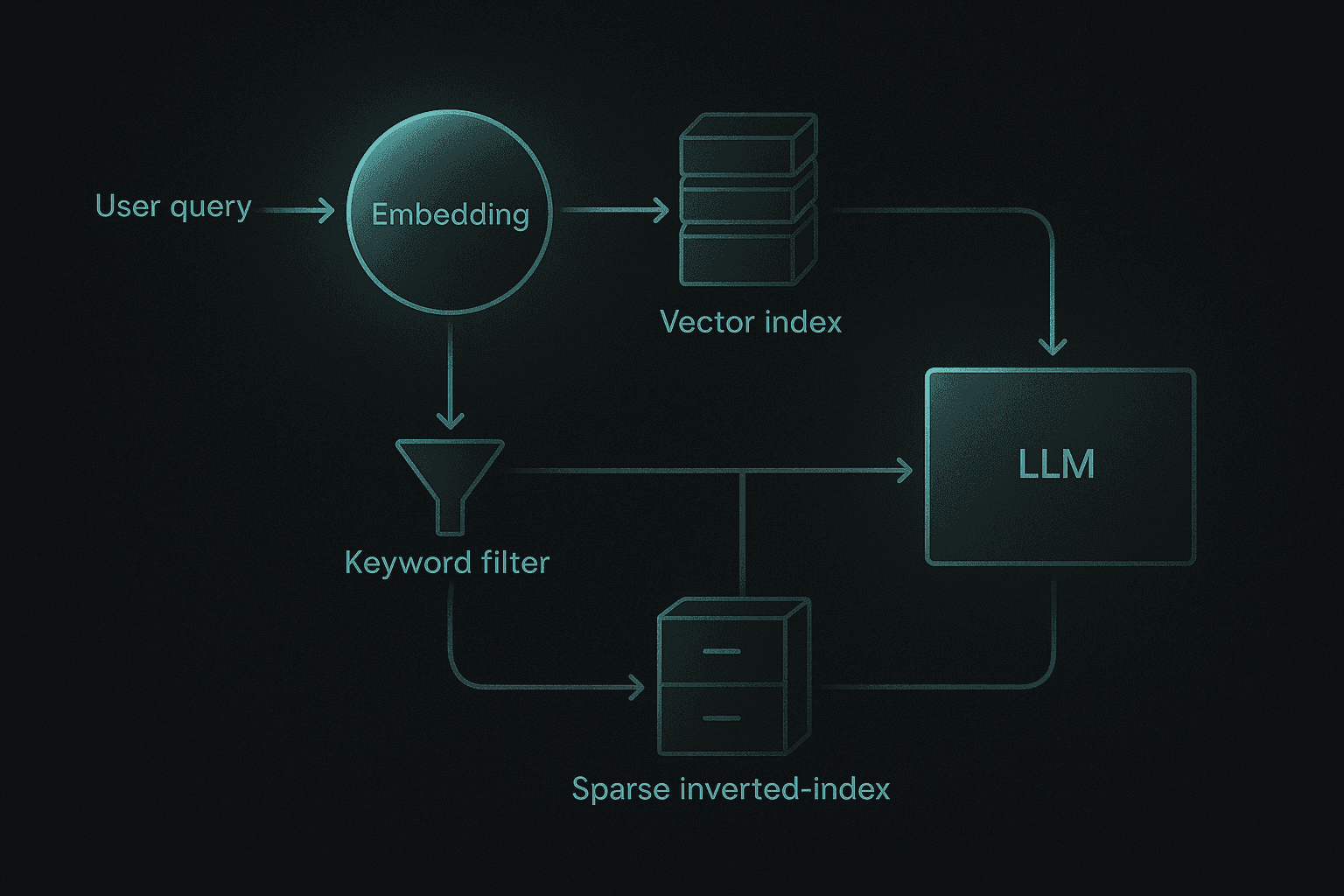
How Does Hybrid Retrieval Boost Accuracy Without Sacrificing Speed?
Architecture alone cannot solve every recall problem. Most production systems rely on retrieval-augmented generation (RAG) to supply context at inference time. The question is which retrieval strategy maximizes accuracy without crushing latency.
Dense vs. sparse vs. hybrid
Dense vector search excels at capturing semantic intent but often struggles with queries that demand high keyword accuracy. Sparse search (BM25) handles exact matches well but misses paraphrases. Hybrid RAG combines both, allowing the system to evaluate documents from semantic and lexical perspectives.
Benchmarks show:
Recall@5 +7.2%: The hybrid model increased Recall@5 from 0.655 to 0.702. (arXiv)
MRR +18.5%: The hybrid system elevated Mean Reciprocal Rank from 0.410 to 0.486. (arXiv)
Latency +24.5%: The hybrid system introduces an additional 201 ms of latency per query.
The latency cost is real, but the accuracy gains often justify it, especially in agentic workflows where a wrong retrieval can derail an entire task chain.
Knowledge graphs for governance and accuracy
Knowledge graphs provide a formal framework to evaluate the validity of a query generated by an LLM, serve as a foundation for explaining results, and offer access to governed and trusted data. One benchmark found that leveraging an ontology to identify semantic errors in SPARQL queries resulted in a 4× accuracy improvement compared to not using a knowledge graph at all.
Fact-verification frameworks
Cross-checking LLM outputs against multiple knowledge sources can reduce hallucinations by 67% without sacrificing response quality. The framework achieves 92% factual accuracy, representing a 28% relative improvement over vanilla LLM baselines.
Key takeaway: Hybrid retrieval, knowledge graphs, and fact-verification layers form a defense-in-depth strategy that raises recall accuracy at every stage of the pipeline.
What Benchmarks Prove Memory Gains in LLM Agents?
If you cannot measure memory, you cannot improve it. Several frameworks now exist to evaluate memory agents systematically.
MemAE and MemoryAgentBench
MemAE is a unified evaluation framework specifically designed for memory agents. It tests four core competencies:
Accurate retrieval
Test-time learning
Long-range understanding
Conflict resolution (or selective forgetting)
MemoryAgentBench transforms existing long-context datasets and introduces new ones -- EventQA and FactConsolidation -- to simulate incremental information processing characteristic of memory agents.
Key metrics to track
Metric | What It Measures | Target Threshold |
|---|---|---|
Recall@k | Percentage of relevant docs in top-k | ≥0.70 for production |
MRR | Rank of first correct answer | ≥0.45 for conversational agents |
d′ (d-prime) | Signal-detection accuracy | GPT-4 rivals human average in 1-back tasks (EMNLP 2024) |
Hallucination rate | % of unverifiable claims | ≤10% after verification layer |
Empirical results reveal that current methods fall short of mastering all four competencies, underscoring the need for further research into comprehensive memory mechanisms.
Key takeaway: Standardized benchmarks like MemAE expose gaps that ad-hoc testing misses; adopt them before you ship.
How to Ship Memory-Aware Agents in Production
Moving from research prototypes to production requires a disciplined engineering approach.
Step 1: Define memory scope
Decide what the agent should remember: session context, user preferences, or enterprise knowledge. Each scope implies different storage, retrieval, and governance requirements.
Step 2: Choose a retrieval backbone
RAG is a generative AI technology in which an LLM references an authoritative data source outside its training data before generating a response. Cloud providers offer managed options:
Azure: GPT-RAG is built on a zero-trust architecture to ensure all components operate within a controlled, isolated environment.
Google Cloud: Vertex AI accelerates the development and deployment of custom agents and provides managed datastores for RAG.
AWS: Amazon Bedrock Knowledge Bases provide retrieval-augmented generation capabilities while maintaining security controls.
Step 3: Instrument continuous evaluation
Agent performance should be verified at each step of the workflow. Log retrieval hits, generation latency, and user feedback to catch drift before it reaches customers.
Step 4: Build reusable memory modules
The best use case is the reuse case. Develop agents for tasks that share similar actions to reduce redundancy and accelerate iteration across product lines.
Production checklist
Hybrid retrieval enabled (dense + sparse)
Knowledge graph for entity disambiguation
Fact-verification layer with confidence scoring
Role-based access control for sensitive documents
Automated redaction pipeline for PII
Memory benchmark suite integrated into CI/CD
Key takeaway: Production-grade memory requires infrastructure, governance, and continuous measurement, not just a clever prompt.
Key Takeaways
Memory is the missing layer. LLMs struggle with recall because they lack a dedicated long-term memory circuit. Acknowledging that constraint is the first step toward solving it.
Cognitive strategies translate. Chunking, schemas, and semantic scaffolding are low-cost interventions that improve recall without model changes.
Architecture matters. Systems like Titans introduce a novel neural long-term memory module that acts as a deep neural network, enabling models to handle contexts exceeding two million tokens.
Hybrid retrieval pays off. Combining dense and sparse search raises Recall@5 by 7% and MRR by 18%, with manageable latency overhead.
Verification closes the loop. Fact-checking against multiple sources can reduce hallucinations by 67% while preserving response quality.
Benchmarks guide progress. Frameworks like MemAE expose gaps in retrieval, learning, understanding, and conflict resolution that ad-hoc tests miss.
Production demands infrastructure. Agent performance should be verified at each step of the workflow, backed by zero-trust security and continuous evaluation.
For teams building AI agents that need to remember, personalize, and evolve, a memory-first approach is no longer optional. Platforms like Cortex treat memory as a first-class primitive, embedding persistent context and self-improving retrieval directly into the agent loop, so your AI gets more accurate with every interaction.
Frequently Asked Questions
Why is memory recall important for large language models?
Memory recall is crucial for large language models as it determines their ability to maintain coherent, multi-turn conversations and avoid hallucinations. Without accurate recall, users may lose trust in the AI, and downstream automation can fail.
What are some common memory-related issues in LLMs?
LLMs often face working-memory bottlenecks, false-memory formation, and reality-monitoring failures. These issues can lead to dropping facts mid-conversation, fabricating plausible but incorrect details, and confusing prompt information with training data.
How can cognitive strategies improve LLM memory recall?
Cognitive strategies like chunking, schemas, and semantic scaffolding can enhance LLM memory recall. These methods help organize information efficiently, reduce ambiguity, and improve the model's ability to retrieve relevant context.
What are some new architectures that improve LLM memory recall?
New architectures like Titans, Memoria, and MEM1 focus on integrating memory as a core component. These systems use techniques like neural long-term memory modules and weighted knowledge graphs to enhance recall and personalization in LLMs.
How does Cortex enhance LLM memory recall?
Cortex enhances LLM memory recall by embedding persistent context and self-improving retrieval directly into the agent loop. This approach allows AI to become more accurate and personalized over time, without the need for manual intervention.
Sources
https://research.google/blog/titans-miras-helping-ai-have-long-term-memory/
https://www.memlab.psychol.cam.ac.uk/pubs/Simons2017%20TICS.pdf
https://www.frontiersin.org/articles/10.3389/fpsyg.2015.01785/pdf
https://openreview.net/pdf/41cee21d98a3b5172a787dd510e4e5f0e91cabc3.pdf
https://www.sciencedirect.com/science/article/pii/S1570826824000441
https://openreview.net/pdf/2b14e3fecd25cd9511348c6a9ad470c2a2161634.pdf
https://aws.amazon.com/solutions/guidance/healthcare-agent-for-amazon-bedrock/
https://cloud.google.com/architecture/generative-ai-rag-using-vertex-ai-gemini-and-vector-search
https://aws.amazon.com/solutions/guidance/secure-rag-application-using-amazon-bedrock/