
How to Refresh or Update Stored LLM Memory [2026 Guide]
Refreshing LLM memory involves three core approaches: retrieval-augmented generation (RAG) for real-time updates, in-weight test-time training like TTT-E2E for context compression, and external memory banks for massive storage reduction. Success requires benchmarking with frameworks like LongMemEval-s spanning 500 questions across temporal reasoning and knowledge updates, while monitoring retrieval precision and memory drift continuously.
At a Glance
• Three refresh strategies: RAG connects to external data sources, TTT-E2E compresses context into weights achieving 2.7× speedup, external memory banks reduce size to 0.3% of baselines
• Benchmark requirements: LongMemEval-s tests 5 core capabilities across 115k+ tokens, LoCoMo evaluates long context memory, MemoryAgentBench measures 4 competencies including selective forgetting
• Cortex performance: Achieved 90.23% accuracy on LongMemEval-s with 94.87% on knowledge updates and 90.97% on temporal reasoning
• Common failures: Catastrophic forgetting from update collisions, temporal confusion without proper timestamping, context fragmentation breaking fact relationships
• Implementation essentials: Smart chunking with metadata labeling, monitoring retrieval precision/recall, versioning knowledge instead of overwriting
Teams building AI agents in 2026 face a critical challenge: how to update stored LLM memory without breaking what already works. Static models trained on yesterday's data produce stale answers today, and the gap between what an agent knows and what it should know grows wider every week.
This guide breaks down the dominant strategies for refreshing LLM memory, explains how to measure whether your updates actually work, and offers a practical checklist for implementing continuous memory in production.
Why Is Updating LLM Memory Mission-Critical in 2026?
Large Language Models have become essential for everyday applications, yet their knowledge quickly becomes outdated as data evolves. The core problem is straightforward: models trained on static datasets cannot adapt to new information without intervention.
"The ability to accurately recall user details, respect temporal sequences, and update knowledge over time is not a 'feature' -- it is a prerequisite for Agentic AI," according to Supermemory's research.
Memory capacity remains a persistent issue with large language models. They struggle with long input sequences due to the high computational cost of memory required by these models. This limitation affects everything from chatbot interactions to enterprise search systems.
Continual learning aims to update LLMs with new information without erasing previously acquired knowledge. This balance between retention and adaptation defines the central challenge for teams shipping production agents.
Key takeaway: Without a robust memory refresh strategy, AI agents deliver increasingly irrelevant responses as the gap between their training data and current reality widens.
Core Strategies to Refresh or Replace Outdated Knowledge
Modern teams combine three main approaches to keep LLM memory current. Each addresses different trade-offs in latency, cost, and accuracy.
TTT-E2E method enables LLMs to compress long context into model weights via next-token prediction. This approach outperforms both transformers with full attention and RNNs like Mamba 2 and Gated DeltaNet in both loss scaling and inference latency.
Memory-augmented approaches equip LLMs with a memory bank as an external module that stores information for future use. These systems can be updated independently of the base model.
Larimar's architecture allows for dynamic, one-shot updates of knowledge without re-training or fine-tuning. This flexibility makes it particularly valuable for applications requiring frequent knowledge changes.
Retrieval-Augmented & Chunking-Based Updates
Retrieval-augmented generation (RAG) connects LLMs to external data sources, which necessitated the creation of chunking systems for segmenting lengthy inputs into manageable pieces.
Key components of RAG-based memory refresh:
Agentic chunking: Uses AI to segment text into semantically coherent blocks rather than fixed-size chunks
Metadata labeling: Applies generative AI to label each chunk for easier retrieval
Inference scaling: Increasing inference computation leads to nearly linear gains in RAG performance when optimally allocated
Vector databases store and retrieve high-dimensional vector data efficiently, making them foundational for RAG implementations. They excel at handling unstructured data including text, images, and audio.
In-Weight Test-Time Training (TTT-E2E)
TTT-E2E represents a shift from architecture design to treating long-context modeling as a continual learning problem. The method compresses context into model weights at inference time.
Performance benchmarks show impressive results:
Metric | TTT-E2E Performance |
|---|---|
128K context speedup | 2.7× faster than full attention |
Inference latency | Constant regardless of context length |
Test loss improvement | 0.018 better even on top of full attention |
Enterprise adoption signals validate this approach. Average reasoning token consumption per organization has increased by approximately 320× in the past 12 months, indicating growing demand for sophisticated memory-capable systems.
However, current implementations face a limitation: the meta-learning phase is 3.4× slower than standard pre-training at short contexts due to lack of support for gradients of gradients in FlashAttention.
External Memory Banks & Compression Layers
External memory systems offer a different path to knowledge updates. MBC (Memory Bank Compression) uses a codebook optimization strategy to compress memory during online adaptation learning.
The compression gains are substantial: MBC reduces the memory bank size to 0.3% of the most competitive baseline while maintaining high retention accuracy.
Larimar provides a brain-inspired architecture with distributed episodic memory. It achieves speed-ups of 4-10× depending on the base LLM while matching accuracy on fact editing benchmarks.
Vector databases remain optimized for similarity search, which is crucial for AI models that rely on finding the most relevant data points quickly.
How Do You Measure Success with LLM Memory Benchmarks?
Validating memory refresh requires purpose-built benchmarks. LongMemEval_s spans 500 questions split into six categories, evaluating five core memory capabilities across high-noise environments with 115k+ tokens of context.
The unified evaluation framework from EverMind benchmarks leading memory systems under consistent datasets, metrics, and answer models, using GPT-4.1-mini to isolate memory backend performance.
MemoryAgentBench was specifically designed for memory agents, addressing gaps in existing benchmarks that do not reflect the interactive, multi-turn nature of production systems.
LongMemEval & LoCoMo Results
The LongMemEval benchmark tests long-term memory evaluation across multiple sessions with knowledge updates. Categories include single-session-user, single-session-assistant, multi-session, temporal-reasoning, and knowledge-update.
Benchmark | Focus Area | Key Categories |
|---|---|---|
LongMemEval | Long-term memory across sessions | Temporal reasoning, knowledge updates |
LoCoMo | Long context memory | Single-hop, multi-hop, temporal, adversarial |
ConvoMem | Conversational memory | Personalization, preference learning |
EverMemOS delivered best-in-class results across both LoCoMo and LongMemEval benchmarks. Supermemory demonstrates particular strength in Multi-Session (71.43%) and Temporal Reasoning (76.69%), areas where standard vector-store approaches historically struggle.
Interactive Agent Benchmarks
MemoryAgentBench identifies four core competencies essential for memory agents:
Accurate Retrieval (AR): The ability to extract the correct snippet in response to a query
Test-Time Learning (TTL): The capacity to incorporate new behaviors during deployment without additional training
Long-Range Understanding (LRU): The ability to integrate information across extended contexts (≥100k tokens)
Selective Forgetting (SF): The skill to revise or remove stored information when faced with contradictory evidence
The benchmark provides a consistent evaluation protocol across diverse agent architectures and datasets, delivering comprehensive insights into performance across all four competencies.
Cortex AI achieved 90.23% overall accuracy on LongMemEval-s, the highest reported score, with particularly strong performance in temporal reasoning (90.97%) and knowledge updates (94.87%).
Implementing Continuous Memory with Cortex: A Practical Guide
Building production memory systems requires attention to both architecture and operational concerns. The goal is to retrieve and utilize what matters, not everything that fits in context.
Vector databases are designed to store and retrieve high-dimensional data efficiently, making them foundational for AI applications requiring fast and accurate data retrieval.
Modern LLM serving requires careful memory management, as usage includes static weights, dynamic activations, and KV caches. Comprehensive evaluations show systems like eLLM achieve 2.32× higher decoding throughput and support 3× larger batch sizes for 128K-token inputs.
Smart Ingestion & Chunking
Effective chunking starts with preprocessing: cleaning data to remove noise that dilutes content quality.
Ingestion checklist:
Preprocess data to remove unnecessary elements before chunking
Use context-aware segmentation rather than fixed-size chunks
Apply metadata labeling to each chunk for retrieval optimization
Maintain token budgets (GPT-3.5 processes up to 4096 tokens, roughly 3000 English words)
Handle structured content (Markdown, LaTeX) with format-aware chunking
Agentic chunking draws from other methods to create overlapping sections and recursive splitting with metadata labels for easier RAG retrieval.
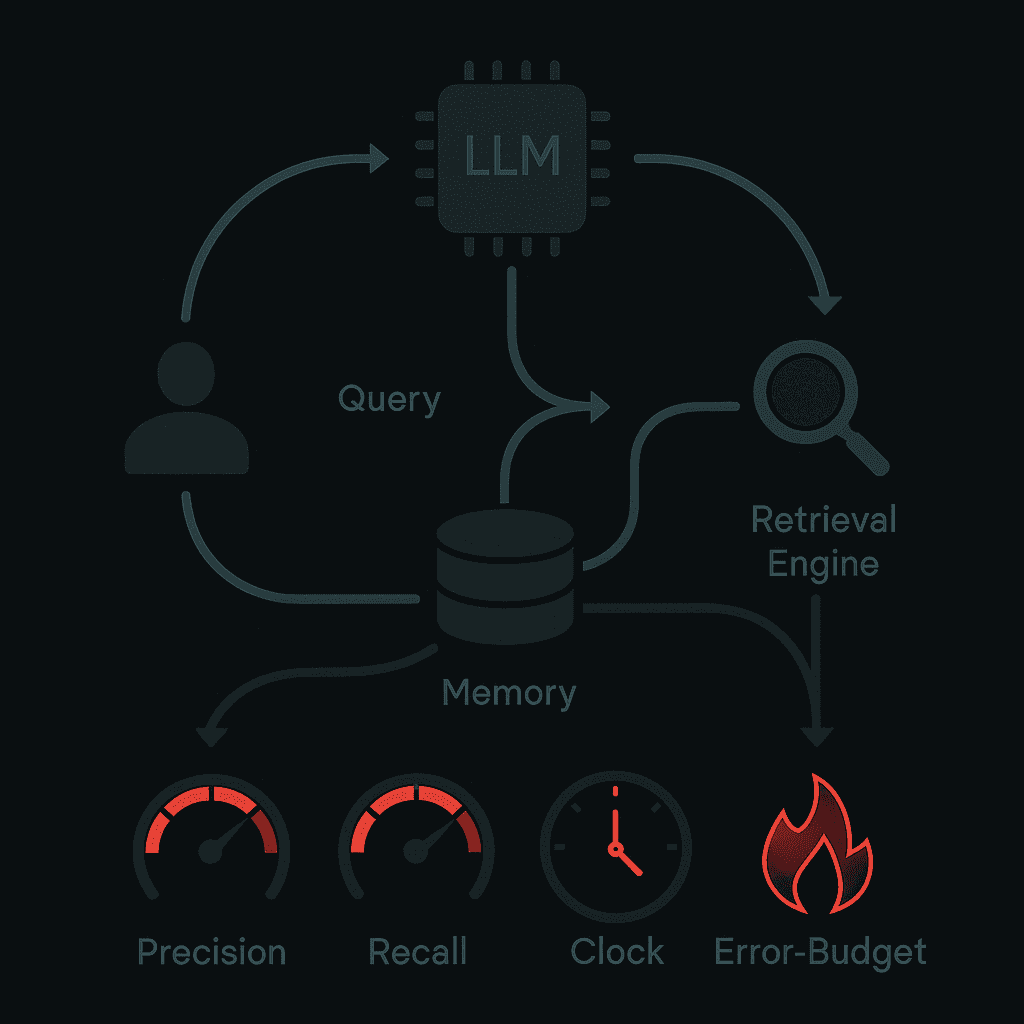
Monitoring Retrieval & Memory Drift
Reliable memory systems require observability. All memory systems should use consistent LLMs for answer generation to isolate memory backend performance when measuring.
Key metrics to track:
Precision: Measures whether every alert corresponds to a significant event
Recall: Measures whether every significant event results in an alert
Detection time: For total outages, 0.6 seconds is achievable
Burn rate: How fast the service consumes error budget relative to SLO
RAG performance consistently improves with expansion of effective context length under optimal configurations. The optimal performance scales nearly linearly with the order of magnitude of inference compute.
What Pitfalls Cause Catastrophic Forgetting—And How Do You Avoid Them?
Continual learning presents a fundamental tension: updating with new information while preserving previously acquired knowledge. When this balance fails, catastrophic forgetting erases what the model once knew.
Empirical results from MemoryAgentBench reveal that current methods fall short of mastering all four core competencies. Most systems struggle with tasks requiring dynamic memory updates and long-range consistency.
Common failure modes:
Retriever dependency: MemR3 and similar systems require an existing retriever or memory structure, and performance depends heavily on that foundation
Temporal confusion: Without proper timestamping, models return outdated information when newer facts exist
Context fragmentation: Breaking context into chunks can sever relationships between related facts
Update collision: New information overwrites related but distinct facts
Mitigation strategies include versioning knowledge rather than overwriting, maintaining temporal markers throughout the memory graph, and validating updates against existing knowledge before committing changes.
What's Next for Agentic Memory Systems?
The research community increasingly recognizes that "memory is not static; it evolves over time." The ICLR 2026 Workshop on Memory for LLM-Based Agentic Systems reflects this focus.
Three perspectives are driving memory layer development:
Memory architectures and representations
Systems and evaluation
Neuroscience-inspired memory
Modern language agents must operate over long-horizon, multi-turn interactions, retrieving external information, adapting to observations, and answering interdependent queries. MEM1, a reinforcement learning framework, demonstrates that agents can solve these tasks with constant context size.
Compact models are showing surprising capability. Orion, a training framework for 350M-1.2B parameter models, performs iterative retrieval through learned strategies. The finding suggests that retrieval performance can emerge from learned strategies, not just model scale.
Cortex is investing in self-improving retrieval that adapts to user interactions, retrieval outcomes, and tenant-level behavior patterns—enabling ongoing improvement without retraining models or rebuilding indexes.
Key Takeaways
Updating stored LLM memory in 2026 requires a layered approach combining retrieval augmentation, in-weight training, and external memory systems.
Choose the right strategy for your latency budget: RAG for real-time updates, TTT-E2E for context-heavy tasks, external memory banks for massive compression
Benchmark rigorously: Use LongMemEval-s, LoCoMo, and MemoryAgentBench to validate across temporal reasoning, knowledge updates, and selective forgetting
Monitor continuously: Track retrieval precision, recall, and drift against SLOs to catch degradation early
Preserve context relationships: Smart chunking and metadata labeling prevent the fragmentation that causes downstream failures
Cortex transforms interactions into durable memory so agents improve over time instead of resetting after each session. Agents remember decisions, states, and outcomes across sessions, delivering the same reliable behavior users expect. For teams building AI agents where accuracy, latency, and long-term learning matter, the memory layer determines whether agents succeed or fail in production.
Frequently Asked Questions
Why is updating LLM memory important in 2026?
Updating LLM memory is crucial because static models trained on outdated data can produce irrelevant responses. As data evolves, AI agents need to adapt to new information to maintain accuracy and relevance.
What are the core strategies for refreshing LLM memory?
Core strategies include retrieval-augmented generation, in-weight test-time training, and external memory banks. Each approach addresses different trade-offs in latency, cost, and accuracy, ensuring LLMs remain up-to-date with current information.
How does Cortex improve LLM memory management?
Cortex enhances LLM memory management by providing a self-improving retrieval and memory layer that adapts to user interactions and retrieval outcomes. This ensures ongoing improvement without the need for retraining models or rebuilding indexes.
What benchmarks are used to measure LLM memory success?
Benchmarks like LongMemEval-s, LoCoMo, and MemoryAgentBench are used to evaluate LLM memory systems. They assess capabilities such as temporal reasoning, knowledge updates, and selective forgetting across high-noise environments.
What are the common pitfalls in LLM memory updates?
Common pitfalls include retriever dependency, temporal confusion, context fragmentation, and update collision. These issues can lead to outdated information being returned or important context being lost.
Sources
https://research.ibm.com/publications/larimar-large-language-models-with-episodic-memory-control
https://singlestore.com/blog/-ultimate-guide-vector-database-landscape-2024
https://evermind.ai/blogs/a-unified-evaluation-framework-for-ai-memory-systems
https://openreview.net/pdf/76b2f887d80606c0afd4152fdf7ff150e48beaf1.pdf