
Why Cortex Outperforms RAG-Only Memory Architectures
Cortex outperforms RAG-only memory architectures by embedding persistent, versioned state directly into the retrieval layer, enabling temporal reasoning and learning from interactions. While RAG achieves only 60% accuracy on single-fact question answering, Cortex achieved 90.23% on the LongMemEval-s benchmark through its time-aware knowledge graph and self-improving retrieval capabilities.
Key Facts
• RAG treats memory as a stateless lookup table with no temporal continuity, causing every query to start from scratch
• Memory-augmented approaches reduce token usage by over 90% while maintaining competitive accuracy, directly cutting operational costs
• Popular LLMs effectively utilize only 10-20% of context, with performance declining sharply as reasoning complexity increases
• Cortex achieved 90.23% overall accuracy on LongMemEval-s, the highest reported score, with particular strength in temporal reasoning and knowledge updates
• Without persistent memory, stateless agents waste 70-80% of context tokens on repeated information, translating to higher costs and slower resolution times
Retrieval-Augmented Generation has become the default strategy for giving large language models access to external knowledge. The approach works by fetching relevant documents at query time and injecting them into the prompt. For simple question-answering, this is often enough.
But RAG was never designed to remember. It treats memory as a stateless lookup table: information persists indefinitely, retrieval is read-only, and temporal continuity is absent. When AI agents need to track evolving user preferences, reason across sessions, or handle knowledge that changes over time, stateless retrieval breaks down.
A memory-first architecture solves these persistent context problems. Rather than bolting retrieval onto an LLM, it embeds memory directly into the retrieval layer, preserving relationships, tracking versions, and learning from interactions. This is what Cortex was built to do.
Why Does Memory-First Architecture Beat Plain RAG?
RAG helps LLMs access external information, but it has a fundamental limitation: every query starts from scratch. There is no continuity between sessions, no learning from past interactions, and no awareness of how information changes over time.
As one research paper on long-horizon agents puts it: "RAG treats memory as a stateless lookup table: information persists indefinitely, retrieval is read-only, and temporal continuity is absent."
Memory is fundamental to how LLM-based agents carry out extended conversations, reason over longer time frames, and act coherently. Without it, agents cannot adapt responses based on what users have told them before. They cannot track when facts became outdated. They cannot build on previous reasoning.
A memory-first architecture addresses these gaps by treating memory as a first-class primitive rather than an afterthought. Instead of simply retrieving documents, it:
Maintains persistent state across interactions
Tracks how knowledge evolves over time
Learns from user behavior and retrieval outcomes
Preserves temporal relationships between facts
Cortex functions as a self-improving retrieval layer that sits between data sources and AI models, handling ingestion, search, personalization, memory, and answer generation out of the box. This eliminates the need to assemble fragmented stacks of vector databases, embedding pipelines, and custom memory systems.
Key takeaway: RAG retrieves; memory-first architectures remember, learn, and evolve.
What Structural Limitations Hold RAG-Only Retrieval Back?
The problems with pure RAG become apparent in production. Three structural limitations consistently emerge.
Limited context utilization. Research on the BABILong benchmark shows that popular LLMs effectively utilize only 10-20% of the context, with performance declining sharply as reasoning complexity increases. RAG methods achieve a modest 60% accuracy on single-fact question answering, regardless of context length.
No episodic learning. RAG retrieves similar documents but cannot distinguish between what happened yesterday versus last year. It has no mechanism for episodic memory, which captures specific past interactions that inform future decisions. Studies show that memory architecture complexity should scale with model capability: foundation models benefit from RAG, but more advanced models need episodic learning and richer semantic structures.
Token waste and cost explosion. Without memory, agents repeat the same context over and over. Research indicates that stateless agents waste 70-80% of context tokens on repeated information. This translates directly to cost: a customer service agent without memory asks users to re-explain problems they described three messages ago.
Limitation | Impact |
|---|---|
Stateless retrieval | No learning across sessions |
No temporal awareness | Cannot track knowledge changes |
Token waste | 70-80% of context is repeated |
Limited reasoning | Only 60% accuracy on single-fact QA |
These limitations explain why teams encounter significant challenges when scaling RAG systems in production. Not because retrieval is conceptually flawed, but because the engineering complexity required to maintain accuracy at scale is often underestimated.
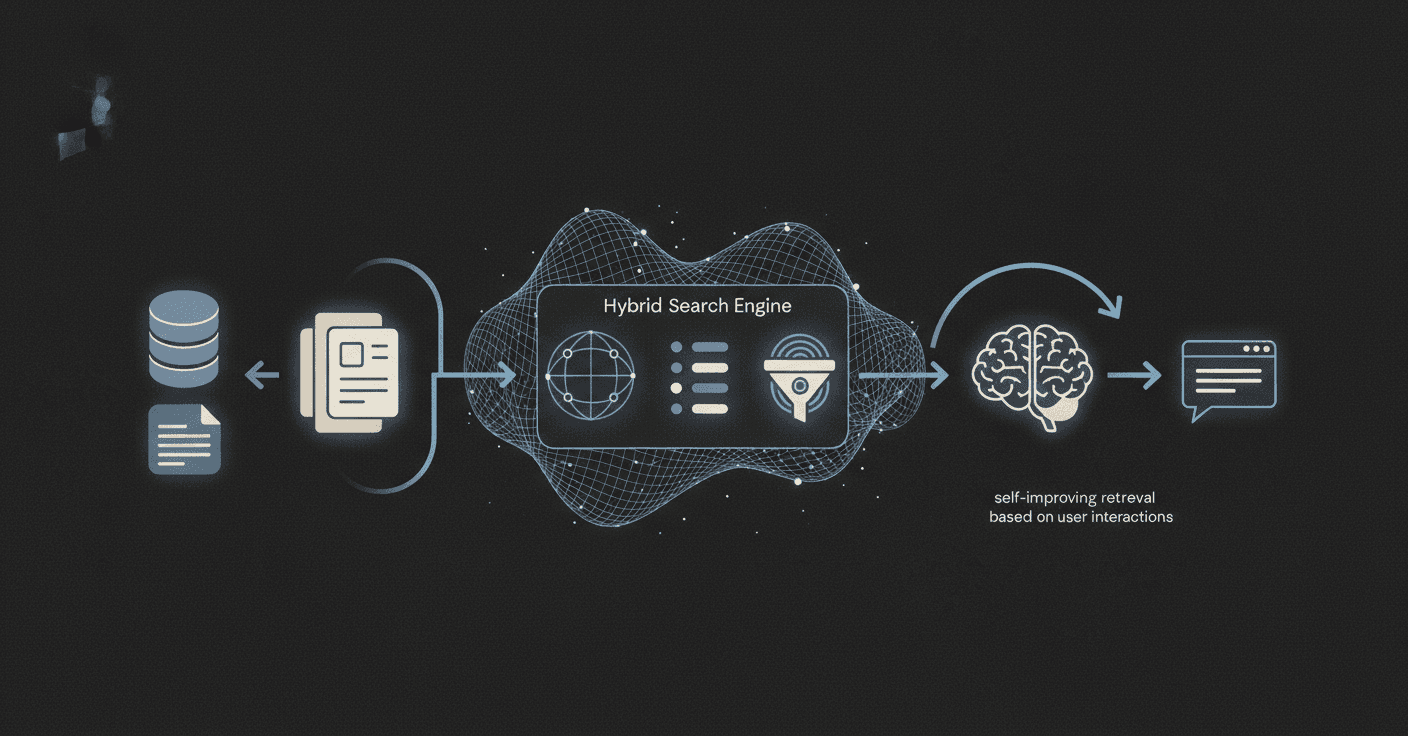
How Does Cortex's Hybrid Memory Layer Work?
Cortex replaces the fragmented RAG stack with an integrated system built on three architectural pillars.
Hybrid search engine. At the core is a hybrid search system that combines semantic vector search, full-text keyword search (BM25), metadata-first filtering, and weighted inference with reranking. Unlike traditional vector databases that search across an entire corpus, Cortex scopes and filters results before retrieval, improving precision and reducing hallucinations.
Built-in memory layer. The platform treats memory as a first-class primitive. It natively supports persistent memory across conversations, user-level personalization, and contextual adaptation over time. Rather than relying on prompt tricks or external stores, memory is embedded directly into the retrieval layer.
Self-improving retrieval. The system continuously improves by learning from user interactions, retrieval outcomes, and tenant-level behavior patterns. This enables ongoing improvement without retraining models or rebuilding indexes.
Time-Aware Knowledge Graph
One of the hardest problems in production AI is handling knowledge that changes. A user's address, job title, or preferences can evolve. Pure RAG has no way to distinguish current facts from outdated ones.
Cortex preserves and enriches contextual relationships during ingestion, mapping every memory into a time-aware, versioned knowledge graph. Each piece of information retains awareness of what came before and after it.
This architecture enables:
New information creates versions rather than overwriting old facts
Temporal queries ("Where did I live before 2023?") return correct answers
Full audit trails show how knowledge changed over time
Research on temporal reasoning shows this capability is critical. The LongMemEval benchmark evaluates five core abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. Systems without temporal awareness show a 30% accuracy drop when memorizing information across sustained interactions.
Frameworks like Memory-T1 demonstrate that time-aware memory selection maintains robustness up to 128k tokens, where baseline models collapse. Cortex's architecture follows similar principles, tracking versions and chronology to enable reliable long-term reasoning.
Benchmark Proof: LongMemEval & Beyond
Claims about memory architecture need quantitative backing. The LongMemEval-s benchmark provides exactly that: 500 curated questions within scalable chat histories, averaging 115,000+ tokens per stack.
Cortex achieved 90.23% overall accuracy, the highest reported score to date, with particularly strong performance in:
Temporal reasoning
Knowledge updates
User preference understanding
These categories represent the hardest failure modes for AI agents in production. By contrast, the BABILong benchmark shows that popular LLMs effectively utilize only 10-20% of context, with performance declining as reasoning complexity increases.
System | LongMemEval-s Accuracy |
|---|---|
Cortex | 90.23% |
Full Context Baseline | 60.2% |
The LongMemEval benchmark itself presents a significant challenge: existing systems show a 30% accuracy drop on memorizing information across sustained interactions. Cortex's architecture specifically targets these failure modes.
What Business Wins Come From a Memory Layer?
Technical advantages translate into measurable business outcomes.
Cost reduction. Research shows that implementing persistent memory reduces context costs by 60%, from $2,400/month to $960/month for 100K conversations, while improving response quality by 35% through learned user preferences. Memory-augmented approaches reduce token usage by over 90% while maintaining competitive accuracy.
Faster resolution times. In one documented case, support resolution time dropped from 8.3 minutes to 3.1 minutes because agents remembered previous interactions, customer preferences, and historical issues.
Lower latency. Studies across multiple datasets confirm that memory-augmented approaches reduce token usage by over 90% while maintaining competitive accuracy. Less context to process means faster responses.
The market has noticed. Data indicates that 67% of enterprise AI deployments plan memory systems in 2026, compared to just 12% in 2025. Memory-augmented agents are becoming table stakes for production AI.
Key takeaway: Adding memory is not just an accuracy upgrade; it delivers direct cost, latency, and resolution time wins.
CMA & Zep vs Cortex: Which Memory Architecture Leads?
Several systems have emerged to address RAG's limitations. Continuum Memory Architecture (CMA) and Zep represent two notable approaches.
Continuum Memory Architecture
CMA is a class of systems that maintain and update internal state across interactions through persistent storage, selective retention, associative routing, temporal chaining, and consolidation into higher-order abstractions.
The research positions CMA as a necessary architectural primitive for long-horizon agents. However, it also acknowledges open challenges around latency, drift, and interpretability. CMA represents a theoretical framework rather than a production-ready system.
Zep's Temporal KG Layer
Zep is a memory layer service built around Graphiti, a temporally-aware knowledge graph engine. It synthesizes unstructured conversational data and structured business data while maintaining historical relationships.
In benchmarks, Zep demonstrates 94.8% accuracy in the Deep Memory Retrieval (DMR) benchmark, with accuracy improvements of up to 18.5% while reducing response latency by 90% compared to baseline implementations.
However, comparing across benchmarks reveals important context. DMR tests different capabilities than LongMemEval-s, which specifically evaluates temporal reasoning, knowledge updates, and user preference understanding across massive 115k+ token contexts. Cortex's 90.23% score on LongMemEval-s reflects performance on these production-critical categories.
System | DMR Benchmark | LongMemEval-s |
|---|---|---|
Zep | 94.8% | Not reported |
Cortex | Not reported | 90.23% |
For enterprises prioritizing temporal reasoning and multi-session context, the benchmark that matters most depends on the use case.
How Do You Migrate from RAG to Cortex?
Migrating from a RAG stack to a memory-first architecture requires careful planning. Based on documented production experiences, here is a practical path.
1. Audit current performance. Measure your baseline. Production RAG systems require balancing multiple constraints: retrieval accuracy, generation quality, latency, cost, security, and operational complexity. Document where your system falls on each.
2. Identify memory gaps. Common failure modes include lack of temporal awareness, repeated context waste, and inability to learn from interactions.
3. Run a parallel pilot. One engineering team documented restoring 99.95%+ uptime under 30x load by restructuring their memory layer. They cut LLM token usage in half while maintaining accuracy above 80% on the LongMemEval benchmark. Start with a subset of traffic to validate improvements.
4. Measure latency impact. Vector indexing in production systems can achieve sub-20ms query latency over 10 million vectors. Ensure your migration maintains or improves current latency SLAs. Graph-based retrieval systems have demonstrated results returning in 150ms (P95), down from 600ms.
5. Plan for scale. Cost structures change at scale. Embedding 1M documents costs $20 with OpenAI's text-embedding-3-small. Embedding 100M documents costs $2,000. A self-improving layer reduces ongoing embedding costs by learning what needs re-indexing.
Key Takeaways
RAG provides retrieval. Memory-first architectures provide learning, adaptation, and temporal awareness.
The differences matter in production:
RAG treats memory as stateless; Cortex maintains persistent, versioned state
RAG retrieves documents; Cortex maps every memory into a time-aware knowledge graph
RAG requires manual assembly of vector databases, embedding pipelines, and orchestration; Cortex provides a fully integrated retrieval engine that adapts automatically
The benchmark evidence is clear: Cortex achieved 90.23% accuracy on LongMemEval-s, the highest reported score, with particular strength in the hardest categories: temporal reasoning, knowledge updates, and user preference understanding.
As one Cortex description states: "Cortex is not a database. It is the retrieval operating system for AI."
For teams building production-grade AI agents where accuracy, latency, personalization, and long-term learning matter, Cortex offers a path beyond the limitations of RAG-only architectures. The engineering complexity of memory-first retrieval is handled at the platform level, letting teams focus on their applications rather than infrastructure.
Frequently Asked Questions
What is the main limitation of RAG-only memory architectures?
RAG-only memory architectures treat memory as a stateless lookup table, lacking continuity between sessions and the ability to learn from past interactions, which limits their effectiveness in tracking evolving user preferences and handling knowledge changes over time.
How does Cortex's memory-first architecture improve AI performance?
Cortex's memory-first architecture embeds memory directly into the retrieval layer, maintaining persistent state across interactions, tracking knowledge evolution, and learning from user behavior, which enhances AI's ability to reason over longer time frames and adapt responses based on past interactions.
What are the business benefits of using Cortex's memory layer?
Implementing Cortex's memory layer can reduce context costs by 60%, improve response quality by 35%, and decrease support resolution times significantly, as it allows AI agents to remember previous interactions and adapt to user preferences.
How does Cortex handle knowledge changes over time?
Cortex uses a time-aware, versioned knowledge graph to preserve and enrich contextual relationships, allowing it to track how knowledge changes over time and provide accurate responses to temporal queries.
What benchmark supports Cortex's performance claims?
Cortex achieved a 90.23% overall accuracy on the LongMemEval-s benchmark, the highest reported score, demonstrating strong performance in temporal reasoning, knowledge updates, and user preference understanding, which are critical for production AI applications.